Hierarchical analyses#
For a pulsar to emit gravitational waves it must have a time varying mass quadrupole. The strength of the observed gravitational-wave signal is proportional to the star’s mass quadrupole moment \(Q_{22}\), which is related to the star’s fiducial ellipticity [1]. Using gravitational-wave observations, an individual pulsar’s \(Q_{22}\) can be estimated, resulting in a posterior probability distribution marginalised over other parameters of the gravitational-wave signal (this can include the pulsar’s distance if a prior on the distance is known). However, a priori, the underlying distribution of \(Q_{22}\) (or equivalently ellipticity) for the pulsar population is unknown. This is where hierarchical Bayesian analysis comes in. If you chose a parameterisable distribution as a prior for the underlying \(Q_{22}\) distribution, then posteriors from multiple gravitational-wave pulsar observations can be combined, included those where no signal is detected, to estimate the parameters (known as hyperparameters) of that distribution [2]. For observations of \(N\) pulsars, the combined data from which is represented by \(\mathbf{D}\), and assuming a prior distribution for \(Q_{22}\) defined by a set of hyperparameters \(\vec{\theta}\), \(p(Q_{22}|\vec{\theta},I)\), then the posterior for \(\vec{\theta}\) is given by:
where \(p(\mathbf{d}_i|{Q_{22}}_i,I)\) is the marginalised likelihood distribution on \(Q_{22}\) for an individual pulsar given it’s observations \(\mathbf{d}_i\), and \(p(\vec{\theta}|I)\) is the prior on the hyperparameters.
The hierarchical module in CWInPy allows the outputs of pulsar parameter estimation for multiple sources to be combined to estimate the hyperparameters of several different potential \(Q_{22}\) (or ellipticity) distributions. To do this it is required that the parameter estimation has been performed using \(Q_{22}\) when defining the signal amplitude, rather than \(h_0\), and that the distance is either assumed to be precisely known, or the parameter estimation has included distance within the estimation via the use of a distance prior.
Evaluating the integral#
Within the CWInPy implementation there are two ways provided of evaluating the integrals in the equation for \(p(\vec{\theta}|\mathbf{D}, I)\).
The first method is to evaluate the integrals numerically. A Gaussian kernel density estimate (KDE) of the posterior distribution \(p({Q_{22}}_i|\mathbf{d}_i,I)\) is generated for each pulsar, which is converted back into the required likelihood distribution via
where \(p({Q_{22}}_i|I)\) is the prior on \(Q_{22}\) used during the parameter estimation and \(p(\mathbf{d}_i|I)\) is the marginal likelihood given the data for the ith pulsar.
The second method uses the fact that the integrals are equivalent to calculating the expectation value of the prior distribution (see, e.g., [3]):
where the term on the right hand side is calculating the mean of the \(Q_{22}\) distribution
evaluated at the \(M\) samples from likelihood. In the case that the prior used for
\(Q_{22}\) during the parameter estimation was not uniform then the
MassQuadrupoleDistribution class will attempt to recreate likelihood
samples by reweighting the posterior samples. In this case the scaling factor from the marginal
likelihood is not included, however, Bayes factors for different distributions using the same data
still can still be calculated.
Note
Both these methods should be equivalent, but as discussed in [2], for the particular case of estimating the pulsar mass quadrupole distribution, the “expectation value” method appears to suffer from numerical issues. This is particularly prominent for cases where to are no significantly detected signals for any pulsar, although it appears to have some effect even when strong signals are present (see the example below). It is not yet clear what the cause of the numerical issues is, but it appears to be related to the reasonably large dynamic range of possible hyperparameters (spanning several orders of magnitude) and the finite sampling of posteriors over that range.
It is therefore, for the moment, recommended to use the numerically evaluated integral based on KDEs of the posteriors.
Available distributions#
The currently allowed distributions are:
a mixture model of bounded Gaussian distributions:
BoundedGaussianDistribution(where the “bounding” refers to the distributions being constrained to positive values as \(Q_{22}\) must be positive)an exponential distribution:
ExponentialDistributiona power law distribution:
PowerLawDistributiona delta function distribution:
DeltaFunctionDistributiona non-parametric histogram-type distribution
HistogramDistribution(see, e.g.,
The MassQuadrupoleDistribution can use any of the above distributions
to define the distribution on the mass quadrupole to be inferred from a set of individual pulsar
mass quadrupole posteriors.
When creating instances of these distributions via the
create_distribution() function the following shorthand names can be used:
"gaussian"for theBoundedGaussianDistribution"exponential"for theExponentialDistribution"powerlaw"for thePowerLawDistribution"deltafunction"for theDeltaFunctionDistribution"histogram"for theHistogramDistribution
with the required hyperparameters as given by DISTRIBUTION_REQUIREMENTS.
These names can also be used for the distribution argument of
MassQuadrupoleDistribution.
Example#
In this example we will use the simulation module to generate a set of pulsars with mass quadrupoles drawn from an exponential distribution and then show how the mean of that exponential distribution can be estimated.
The code below will generate a HTCondor DAG that will simulate 100 pulsars with \(Q_{22}\)
values drawn from an exponential distribution with a mean of \(\mu = 10^{30}\,
{\textrm{kg}}\,{\textrm m}^2\). The pulsars’ sky locations will be drawn uniformly over the sky and
from the default uniform distance distribution. The orientations of the pulsars will also be drawn
from the default uniform distributions, which are described in the
PEPulsarSimulationDAG documentation. The simulation will only
generate observations from a single gravitational-wave detector, the LIGO Hanford detector (“H1”),
in this case.
The parameter estimation performed on each of these pulsars will use a uniform prior on \(Q_{22}\), a uniform prior over the orientation parameters (within the non-degenerate ranges), and will assume the distance to each is precisely know and equal to the simulated value.
from cwinpy.pe.simulation import PEPulsarSimulationDAG
from bilby.core.prior import PriorDict, Uniform, Exponential, Sine
# set the Q22 distribution
mean = 1e30
q22dist = Exponential(name="q22", mu=mean)
# set the prior for each pulsar
prior = PriorDict({
"q22": Uniform(0.0, 1e38, name="q22"),
"iota": Sine(name="iota"),
"phi0": Uniform(0.0, np.pi, name="phi0"),
"psi": Uniform(0.0, np.pi / 2, name="psi"),
})
# set the detector
detectors = ["H1"]
npulsars = 100 # number of pulsars to simulate
# generate and submit the simulation DAG
run = PEPulsarSimulationDAG(
ampdist=ampdist,
prior=prior,
npulsars=npulsars,
detector=detectors,
basedir="/home/user/exponential", # base directory for analysis output
submit=True, # automatically submit the HTCondor DAG
numba=True, # use numba for likelihood evaluation
sampler_kwargs={'Nlive': 1000, 'sample': 'rwalk'},
)
Note
If running on LSC DataGrid computing resources the accountuser argument may be required
to set the HTCondor accounting_group_user variable to your albert.einstein@ligo.org
username, and accountgroup may be required to set the accounting_group variable to a
valid accounting tag. You may also need to run
ligo-proxy-init -p albert.einstein prior to submitting the HTCondor DAG that is generated.
Once the parameter estimation jobs have completed there should be a results directory within the
directory specified by the basedir argument to
PEPulsarSimulationDAG, which contains the results from each pulsar in
the simulation. These can be combined to infer the hyperparameter of the \(Q_{22}\)
distribution. Here we show how to do this using both methods of evaluating the marginalisation
integrals described above, and estimating the posterior on the
hyperparameters using both stochastic sampling (in this case using the nested sampling algorithm
implemented in dynesty) and over a grid of points. The former methods is maybe over-the-top for this
single dimensional example, but does have the advantage that the range and resolution of the
required grid does not need to be known a priori.
Sampling the hyperparameters#
To start with, the results for each pulsar need to be read in. This can be done using a bilby
ResultList object using (assuming the base directory given above):
import glob
from bilby.core.result import ResultList
# get a list of result files
resultfiles = glob.glob("/home/user/exponential/results/J*/*.json")
# read in as list of bilby Result objects
data = ResultList(resultfiles)
Then a MassQuadrupoleDistribution needs to be set up and provided with
the type of distribution for which the hyperparameters will be estimated, the priors on those
hyperparameters, the method of evaluating the integrals, and any
arguments required for the stochastic or grid-based sampling method. In this case the distribution
is an exponential, and we will use a HalfNormal prior (a
Gaussian distribution with a mode a zero, but excluding negative values) for the hyperparameter
\(\mu\), with a scale parameter \(\sigma = 10^{34}\,{\textrm{kg}}\,{\textrm m}^2\) roughly
based on the largest sustainable quadrupole deformations as described in [1].
The first example below uses the integral evaluation method that performs the integrals over
\(Q_{22}\) numerically with the trapezium rule, which requires the "numerical" argument, and
uses the default nested sampling routine to draw the samples from \(\mu\).
# set the distribution type
distribution = "exponential"
# set the hyperparameter prior distribution using a dictionary
sigma = 1e34
distkwargs = {"mu": HalfNormal(sigma, name="mu")}
# integration method
intmethod = "numerical" # use the numerical trapezium rule integration over Q22
# set the sampler keyword arguments
sampler_kwargs = {
"nlive": 500,
"gzip": True,
"outdir": "exponential_distribution",
"label": intmethod,
"check_point_plot": False,
}
# create the MassQuadrupoleDistribution object
mqd = MassQuadrupoleDistribution(
data=data,
distribution="exponential",
distkwargs=distkwargs,
sampler_kwargs=sampler_kwargs,
integration_method=intmethod,
nsamples=500, # number of Q22 samples to store/use
)
# run the sampler
res = mqd.sample(sample="unif")
The res value returned by sample() will be
a Result object containing the posterior samples for \(\mu\).
Note
If you have a very large number of pulsars it may not be memory efficient to read them all in in
one go to a ResultList object. They can instead be passed one at a
time to the MassQuadrupoleDistribution, using the
add_data() method, e.g.:
resultfiles = glob.glob("/home/user/exponential/results/J*/*.json")
mqd = MassQuadrupoleDistribution(
data=resultfiles[0], # add first file
distribution="exponential",
distkwargs=distkwargs,
sampler_kwargs=sampler_kwargs,
integration_method=intmethod,
nsamples=500,
)
# add in the rest of the data files
for resfile in resultfiles[1:]:
mqd.add_data(resfile)
To instead use the method of approximating the integrals over \(Q_{22}\) using the expectation
value of the distribution, the integration_method argument would be set of "expectation".
Rather than stochastically drawing samples from the \(\mu\) posterior distribution, one can
instead evaluate the distribution on a grid. To do this the grid keyword argument can be used to
pass a dictionary, keyed on the hyperparameter names and with values giving the grid points, e.g.,:
# set the grid on mu (in logspace)
muvalues = np.logspace(np.log10(1e27), np.log10(5e34), 1000)
muvalues = np.insert(muvalues, 0, 0) # let's add in a point at zero
grid = {"mu": muvalues}
mqd = MassQuadrupoleDistribution(
data=resultfiles[0], # add first file
distribution="exponential",
distkwargs=distkwargs,
integration_method=intmethod,
grid=grid,
)
# evaluate on the grid
resgrid = mqd.sample()
# get posterior from grid
postgrid = np.exp(resgrid.ln_posterior - resgrid.ln_posterior.max())
postgrid = postgrid / np.trapz(postgrid, muvalues)
In this case the resgrid value returned by
sample() will be a
Grid object.
For comparison, we can plot the results from these different methods as below (assuming the
Result output of using the “expectation value” method is stored in
res2):
from matplotlib import pyplot as plt
from matplotlib import rc
# set fonts
rc("mathtext", **{"fontset": "stix"})
rc("font", **{"family": "STIXGeneral"})
# plot posteriors on the exponential distribution hyperparameter mu
fig, ax = plt.subplots(figsize=(8,6))
scale = 1e30 # scale values so histogram works with density=True argument
truth = 1e30 # the known simulation values of mu
ax.hist( # posterior using "numerical" method
res.posterior["mu"] / scale,
density=True,
histtype="stepfilled",
alpha=0.5,
color="blue",
bins=25,
label="\"numerical\"",
)
ax.hist( # posterior using "expectation value" method
res2.posterior["mu"] / scale,
density=True,
histtype="stepfilled",
alpha=0.5,
color="orange",
bins=25,
label="\"expectation\"",
)
# over plot the distribution as evaluated on a grid
ax.plot(muvalues / scale, postgrid * scale, "darkblue", label="grid")
# add a line showing the "truth"
ax.axvline(truth / scale, color="k", ls="--", lw=2, label="true $\mu$")
ax.set_xlim([0, 4])
ax.set_xlabel(r"$\mu$ ($10^{30}\,{\rm kg}\,{\rm m}^2$)", fontsize=18);
ax.set_ylabel(r"$p(\mu|\mathbf{D}, I)$ ($10^{-30}\,{\rm kg}^{-1}\,{\rm m}^{-2}$)", fontsize=18);
# set axis label font size
for item in ax.get_xticklabels() + ax.get_yticklabels():
item.set_fontsize(14)
# add legends
leg1 = plt.legend(
handles=ax.get_legend_handles_labels()[0][2:],
title="Integration method",
fontsize=14,
title_fontsize=15,
loc="upper right",
)
leg2 = plt.legend(
ax.get_lines()[0:2],
ax.get_legend_handles_labels()[1][0:2],
loc="lower right",
fontsize=14,
)
ax.add_artist(leg1)
ax.add_artist(leg2)
fig.tight_layout()
fig.savefig("muposterior.png", dpi=200)
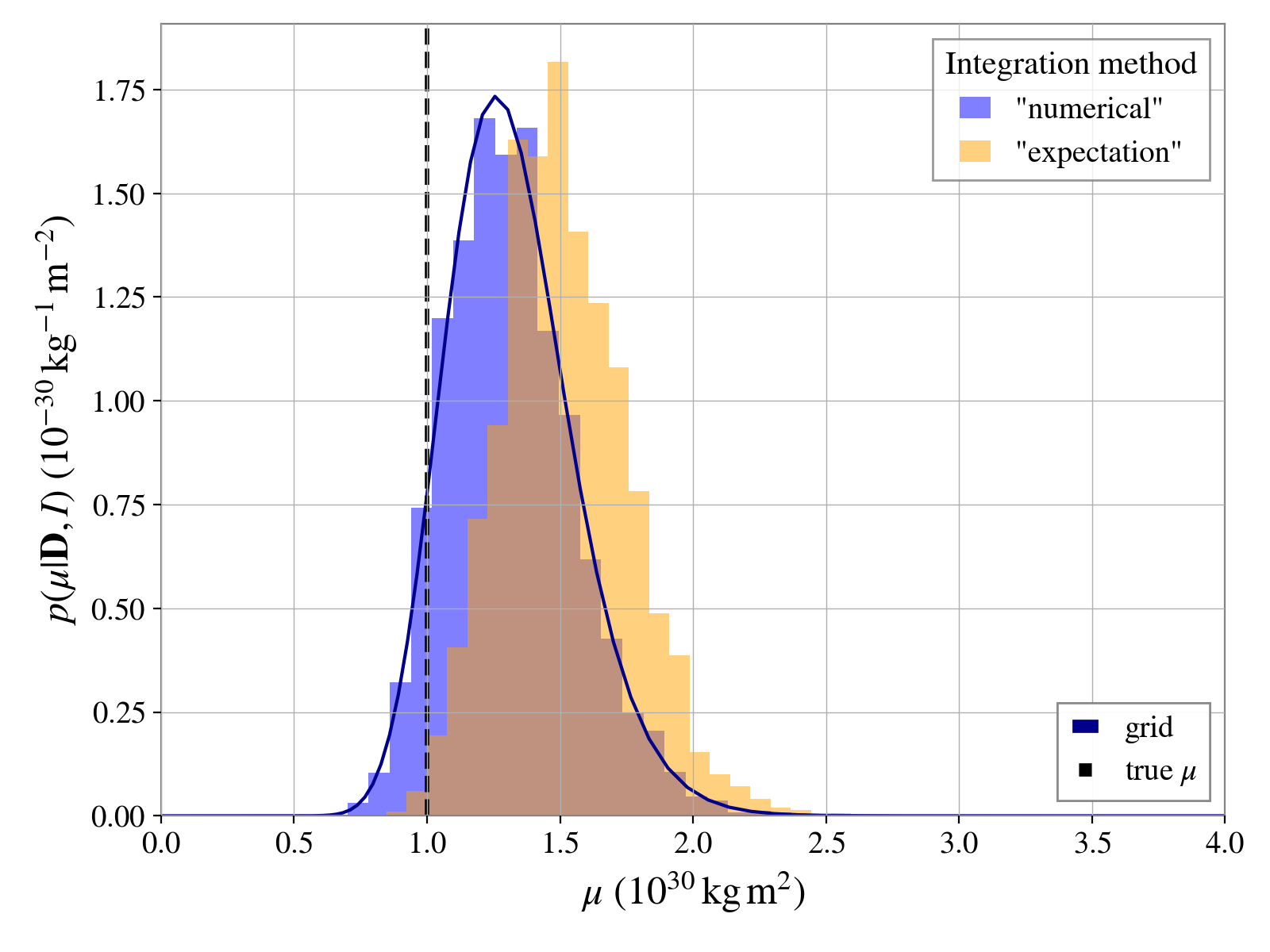
It is interesting to look at the distribution of the signal-to-noise ratios of the simulation versus the recovered maximum a-posteriori signal to noise ratios. Another informative plot is a posterior predictive plot that checks the recovered exponential distribution matches the simulated distribution of \(Q_{22}\) values. Both these are shown below.
from bilby.core.prior import Exponential
from cwinpy import PulsarParameters
import glob
import json
from matplotlib import pyplot as plt
from matplotlib import rc
# true mu value
truth = 1e30
scale = 1e30 # scale values so histogram works with density=True argument
# load in SNRs
snrfiles = glob.glob("/home/user/exponential/results/J*/*snr")
injsnrs = []
recsnrs = []
for sf in snrfiles:
with open(sf, "r") as fp:
d = json.load(fp)
injsnrs.append(d["Injected SNR"])
recsnrs.append(d["Maximum a-posteriori SNR"])
# load in simulation pulsar parameters and extract Q22 values
pulsarfiles = glob.glob("/home/user/exponential/pulsars/*.par")
trueq22 = np.array([PulsarParameters(pf)["Q22"] for pf in pulsarfiles])
# create plot
rc("mathtext", **{"fontset": "stix"})
rc("font", **{"family": "STIXGeneral"})
rc("font", **{"size": 16})
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
# plot true SNR vs recovered SNR
ax[0].plot(injsnrs, recsnrs, "bo", markersize=10, alpha=0.5)
ax[0].set_xscale("log")
ax[0].set_yscale("log")
ax[0].set_xlabel("Injected SNR", fontsize=16);
ax[0].set_ylabel("Maximum a-posteriori SNR", fontsize=16);
# plot posterior predictive
nsamples = 500 # get 500 samples to use for posterior predictive plot
q22values = np.logspace(28, np.log10(2 * np.max(trueq22)), 10000)
for pdf in mqd.posterior_predictive(q22values, nsamples=nsamples):
ax[1].plot(q22values / scale, pdf * scale, color="orange", alpha=0.05)
ax[1].plot( # add "true" distribution
q22values / scale,
Exponential(mu=truth / scale, name="mu").prob(q22values / scale),
color='k',
lw=2,
ls="--",
)
# add histogram and rug plot of simulated Q22 values
ax[1].plot(trueq22 / scale, np.zeros_like(trueq22), '|', color='k', ms=15, alpha=0.5)
ax[1].hist(trueq22 / scale, bins=15, histtype="step", density=True)
ax[1].set_xlim([0, q22values.max() / scale])
ax[1].set_xlabel(r"$Q_{22}$ ($10^{30}\,{\rm kg}\,{\rm m}^2$)", fontsize=16)
ax[1].set_ylabel(r"$p(Q_{22}|\mathbf{D}, I)$", fontsize=16)
ax[1].set_title("Posterior predictive check", fontsize=17)
fig.tight_layout()
fig.savefig("muposteriorpredictive.png", dpi=200)
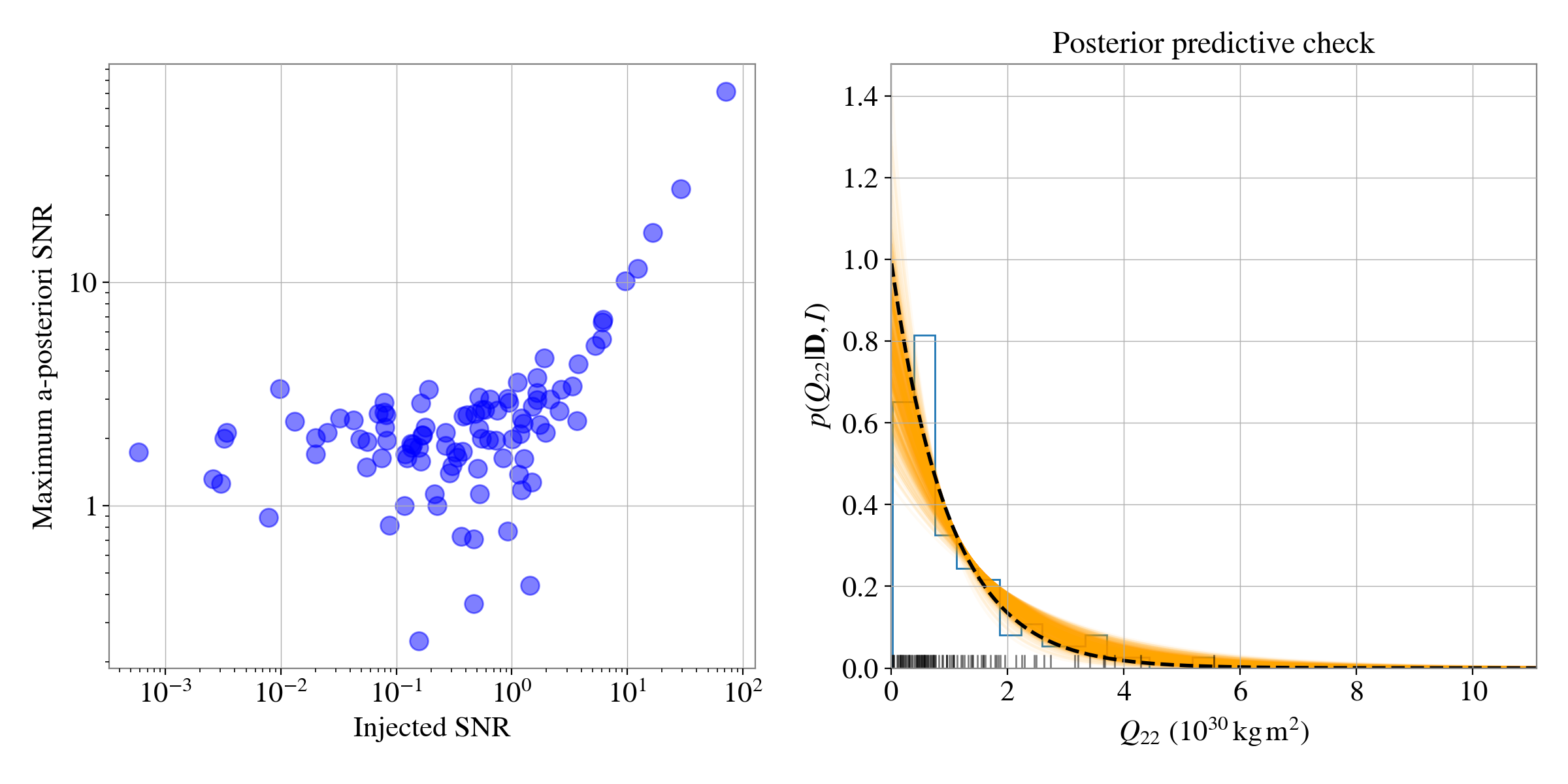
It can be seen that the recovered exponential distributions agree well with the true distribution of \(Q_{22}\) values generated in the simulation.
Model comparison#
We can estimate the hyperparameters of a different distribution based on the same simulated pulsar population. From this we can use the calculated marginal likelihoods for the two distributions to compare which distribution fits the data best.
Below, we use chose to try and fit another simple distribution with a single hyperparameter, a
BoundedGaussianDistribution distribution. This distribution can be
used to fit a mixture model of Gaussians to the data (bounded at zero, so that only positive values
are allowed), but here we will just assume a single mode. The peak of the mode will be fixed at zero
and the width, \(\sigma\), will be given a HalfNormal
prior with the same scale of \(\sigma = 10^{34}\,{\textrm{kg}}\,{\textrm m}^2\) as used for
\(\mu\) previously.
Note
Within a BoundedGaussianDistribution the distribution modes will be
held as parameters called muX, the widths will be held as parameters called sigmaX, and
the mode weights will be held as parameters called weightX, where X will be an index for
the mode starting at zero. E.g., for a distribution defined with a single mode, the parameters
held will be mu0, sigma0 and weight0.
# set up a Gaussian distribution (bounded at zero) with one mode at zero and
# a width to be fitted using sigma
sigma = 1e34
distkwargs = {
"mus": [0], # fix the peak of the single mode at zero
"sigmas": [HalfNormal(sigma, name="sigma")], # set prior on width of the mode
"weights": [1],
}
distribution = "gaussian" # the keyword to use a bounded Gaussian distribution
sampler_kwargs = {
"sample": "unif",
"nlive": 500,
"gzip": True,
"outdir": "gaussian_distribution",
"label": "test",
"check_point_plot": False,
}
bins = 500
mqdgauss = MassQuadrupoleDistribution(
data=data,
distribution=distribution,
distkwargs=distkwargs,
bins=bins,
sampler_kwargs=sampler_kwargs,
)
# sample from the sigma hyperparameters
resgauss = mqdgauss.sample()
We can get the Bayes factor between the two distributions with:
# get the base-10 log Bayes factor between the two models (exponential
# distribution as the numerator and Gaussian as the denominator
bayesfactor = res.log_10_evidence - resgauss.log_10_evidence
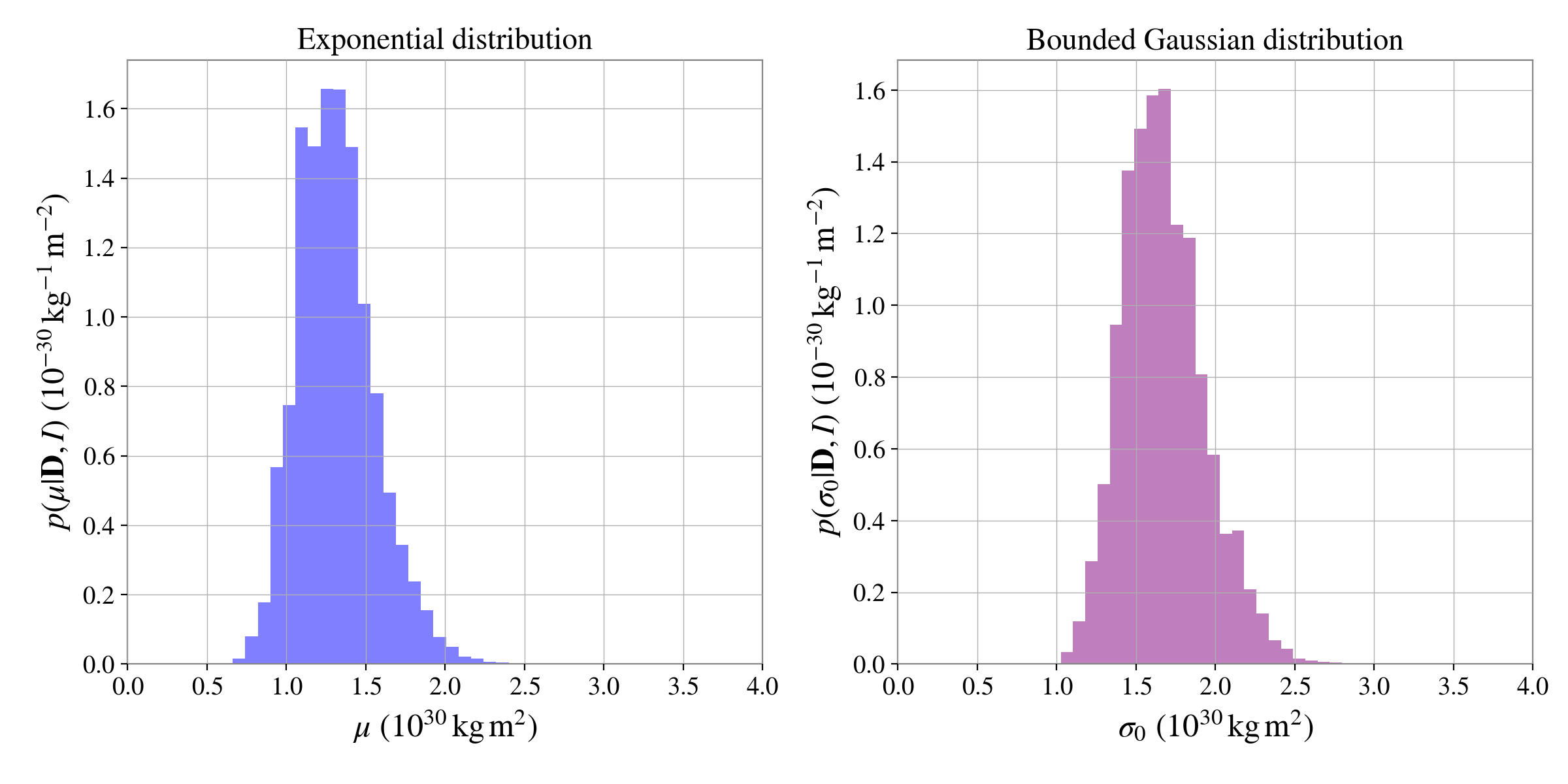
In this case the bayesfactor value is -0.75, i.e., the bounded Gaussian distribution is actually
favoured over the (true) exponential distribution by a factor of \(10^{0.75} = 5.6\)! A Bayes
factor of ~6 is not convincing evidence to favour one model over the other,
but it shows that in some cases it can be tricky to distinguish between distributions.
We can plot the posterior distributions for the hyperparameters from the exponential and Gaussian distributions side-by-side:
# plot posteriors on the exponential distribution hyperparameter mu
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
scale = 1e30 # scale values so histogram works with density=True argument
# plot mu from exponential distribution
ax[0].hist(
res.posterior["mu"] / scale,
density=True,
histtype="stepfilled",
alpha=0.5, color="blue",
bins=25,
)
# plot sigma from gaussian distribution
ax[1].hist(
resgauss.posterior["sigma0"] / scale,
density=True,
histtype="stepfilled",
alpha=0.5, color="purple",
bins=25,
)
ax[0].set_xlim([0, 4])
ax[0].set_xlabel(r"$\mu$ ($10^{30}\,{\rm kg}\,{\rm m}^2$)", fontsize=18)
ax[0].set_ylabel(r"$p(\mu|\mathbf{D}, I)$ ($10^{-30}\,{\rm kg}^{-1}\,{\rm m}^{-2}$)", fontsize=18)
ax[0].set_title("Exponential distribution")
ax[1].set_xlim([0, 4])
ax[1].set_xlabel(r"$\sigma_0$ ($10^{30}\,{\rm kg}\,{\rm m}^2$)", fontsize=18)
ax[1].set_ylabel(r"$p(\sigma_0|\mathbf{D}, I)$ ($10^{-30}\,{\rm kg}^{-1}\,{\rm m}^{-2}$)", fontsize=18)
ax[1].set_title("Bounded Gaussian distribution")
fig.tight_layout()
fig.savefig("musigmaposterior.png", dpi=200)
The trickiness of distinguishing the distributions in this case is highlighted using the posterior predictive plots:
fig, ax = plt.subplots(1, 2, figsize=(12, 6), sharey=True)
# plot posterior predictive for exponential distribution
nsamples = 500 # get 500 samples to use for posterior predictive plot
q22values = np.logspace(28, np.log10(2 * np.max(trueq22)), 10000)
scale = 1e30 # scale values so histogram works with density=True argument
for pdf in mqd.posterior_predictive(q22values, nsamples=nsamples):
ax[0].plot(q22values / scale, pdf * scale, color="orange", alpha=0.05)
ax[0].plot( # add "true" distribution
q22values / scale,
Exponential(mu=truth / scale, name="mu").prob(q22values / scale),
color='k',
lw=2,
ls="--",
)
# add histogram and rug plot of simulated Q22 values
ax[0].plot(trueq22 / scale, np.zeros_like(trueq22), '|', color='k', ms=15, alpha=0.5)
ax[0].hist(trueq22 / scale, bins=15, histtype="step", density=True)
ax[0].set_xlim([0, q22values.max() / scale])
ax[0].set_xlabel(r"$Q_{22}$ ($10^{30}\,{\rm kg}\,{\rm m}^2$)", fontsize=16)
ax[0].set_ylabel(r"$p(Q_{22}|\mathbf{D}, I)$", fontsize=16)
ax[0].set_title("Exponential distribution", fontsize=17)
# plot posterior predictive for bounded Gaussian distribution
for pdf in mqdgauss.posterior_predictive(q22values, nsamples=nsamples):
ax[1].plot(q22values / scale, pdf * scale, color="red", alpha=0.05)
ax[1].plot( # add "true" distribution
q22values / scale,
Exponential(mu=truth / scale, name="mu").prob(q22values / scale),
color='k',
lw=2,
ls="--",
)
# add histogram and rug plot of simulated Q22 values
ax[1].plot(trueq22 / scale, np.zeros_like(trueq22), '|', color='k', ms=15, alpha=0.5)
ax[1].hist(trueq22 / scale, bins=15, histtype="step", density=True)
ax[1].set_xlim([0, q22values.max() / scale])
ax[1].set_xlabel(r"$Q_{22}$ ($10^{30}\,{\rm kg}\,{\rm m}^2$)", fontsize=16)
ax[1].set_title("Bounded Gaussian distribution", fontsize=17)
fig.tight_layout()
fig.savefig("musigmaposteriorpredictive.png", dpi=200)
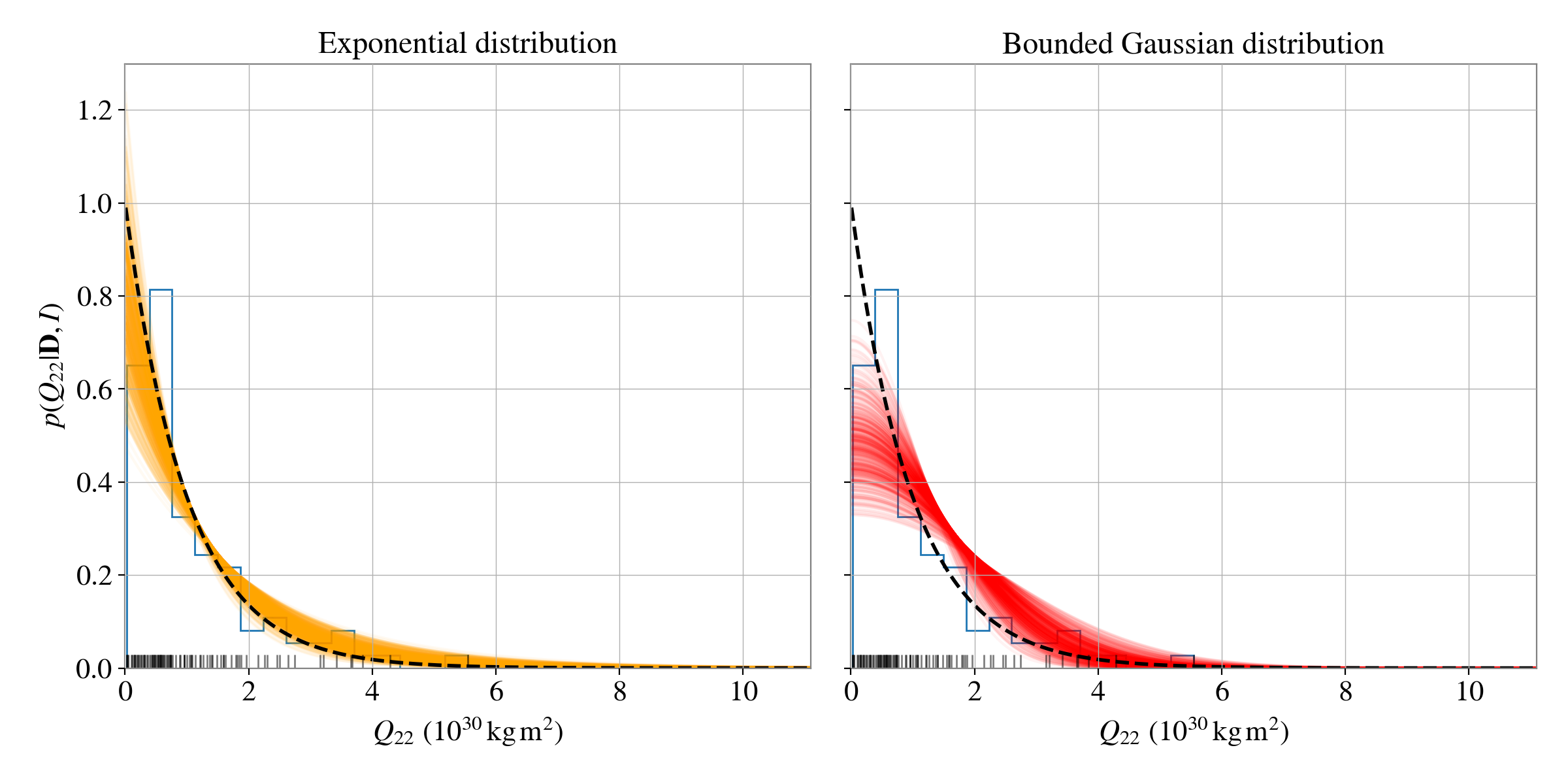
We can see that both models do a reasonable job at recovering the simulated distribution.