Heterodyning data#
Gravitational-wave strain data is often sampled at rates of 4096 Hz or 16384 Hz. It is only feasible to perform parameter estimation for a continuous gravitational-wave signal from a particular pulsar using data that is heavily downsampled compared to this rate. As described in Heterodyned Data, this is done using the method from [1]. The pulsar’s phase evolution is assumed to be well described by a Taylor expansion
where \(f_0\) is the source rotation frequency, \(\dot{f}_0\) is the first frequency derivative, \(t'\) is the time in a frame at rest with respect to the pulsar (the pulsar proper time, which for isolated pulsars is assumed to be consistent with the solar system barycentre), \(T_0\) is the time reference epoch in the pulsar proper time, and \(C\) is an emission mechanism-dependent scaling factor (often set to 2, for emission from the \(l=m=2\) quadrupole mode).
Note
The analysis code described below can use a Taylor expansion in the phase up to arbitrarily high orders. The model can also include terms in addition to this expansion, such as those describing the evolution of the phase following a glitch (using the model described in Eqn. 1 of [2]) and sinusoidal terms to whiten timing noise (using the model described in Eqn. 10 of [3]).
The raw real time series of \(h(t)\) from a detector is “heterodyned”,
to remove the high-frequency variation of the potential source signal, where \(\Delta t(t)\) is a time-, source- and detector-position-dependent delay term that accounts for the Doppler and relativistic delays between the time at the detector and the pulsar proper time (see, e.g., Equation 1 of [3]). The resulting complex series \(h'(t)\) is low-pass filtered (effectively a band-pass filter on the two-sided complex data) using a high order Butterworth filter with a given knee frequency, and down-sampled, via averaging, to a far lower sample rate than the original raw data. In general, gravitational-wave detector data is sampled at 16384 Hz, and often the heterodyned data is downsampled to 1/60 Hz (one sample per minute).
CWInPy can be used to perform this heterodyning, taking files containing raw gravitational-wave
strain and returning the complex, filtered, down-sampled time series in a form that can be read in
as a HeterodynedData object. To generate the phase evolution used for the
heterodyne, CWInPy can either use functions within LALSuite (the default) or, if installed, use the Tempo2 pulsar timing package (via the libstempo wrapper package).
CWInPy comes with an executable, cwinpy_heterodyne, for implementing this, which closely (but
not identically) emulates the functionality from the LALSuite code lalpulsar_heterodyne (formerly
lalapps_heterodyne_pulsar).
There is also an API for running this analysis from within a Python shell or script as described below.
Running the analysis#
The cwinpy_heterodyne executable and API can be used to process
gravitational-wave data for individual pulsars or multiple pulsars. We will cover some examples of
running analyses via use of command line arguments, a configuration file supplied to
cwinpy_heterodyne, or through the API. The current command line arguments
for cwinpy_heterodyne are given below.
If running an analysis for multiple pulsars on a large stretch of data it is recommended that you
split the analysis up to run as many separate jobs. If you have access to a computer cluster (such
as those available to the LVK, or via the Open
Science Grid), or an individual machine (see below), running the
HTCondor job scheduler system then the analysis can
be split up using the cwinpy_heterodyne_pipeline pipeline script (see Running using HTCondor).
Note
For LVK users, if requiring access to proprietary IGWN frame data (i.e., non-public frames visible to those within the LVK collaboration) via CVMFS rather than frames locally stored on a cluster, you will need to generate a SciToken to allow the analysis script to access them. To enable the pipeline script to find science segments and frame URLs you must generate a token with:
htgettoken -a vault.ligo.org -i igwn
Warning
On some systems still using the X.509 authentication you may instead need to run
ligo-proxy-init -p albert.einstein
to find the science segments and frame URLs.
and then run:
condor_vault_storer -v igwn
to allow the HTCondor jobs to access the credentials.
By default, if you specify the datafind server host as datafind.ligo.org for a
cwinpy_heterodyne_pipeline job, it will assume that you are using SciToken authentication
when creating the HTCondor DAG. You can force the requirement of using SciToken by adding
use_scitokens = True
in the job configuration file.
The cwinpy_heterodyne_pipeline should be used for most practical purposes, while
cwinpy_heterodyne is generally useful for short tests.
In many of the examples below we will assume that you are able to access the open LIGO and Virgo data available from the GWOSC via CVMFS. To find out more about accessing this data see the instructions here. If using GWOSC data sampled at 4 kHz it should be noted that that this has a low-pass filter applied that causes a sharp drop-off above about 1.6 kHz, which is below the Nyquist rate. Therefore, if analysing sources with gravitational-wave signal frequencies greater than about 1.6 kHz the 16 kHz sample rate data should be used.
In the examples below, times will be defined using GPS seconds.
Note
To run a heterodyne analysis as multiple jobs on your own machine with HTCondor see Local use of HTCondor.
Example: two simulated pulsar signals#
For the first example, we will generate some simulated data containing signals from two (fake) pulsars. To make the simulation manageable in terms of the amount of data and to have a quick run time we will generate only one day of data at a sample rate of 16 Hz (the standard LIGO/Virgo sample rate is 16384 Hz).
Generating the data#
To generate the data we will use the LALSuite programme
lalpulsar_Makefakedata_v5 (you can skip straight to the heterodyning description
here). The two fake pulsars have parameters defined in Tempo(2)-style
parameter files (where frequencies, frequency derivatives and phases are the rotational values
rather than the gravitational-wave values), as follows:
an isolated pulsar in a file called
J0123+0123.par
PSRJ J0123+0123
RAJ 01:23:00.0
DECJ 01:23:00.0
F0 3.4728
F1 -4.93827e-11
F2 1.17067e-18
PEPOCH 55818.074666481479653
EPHEM DE405
UNITS TDB
H0 3.0e-24
PHI0 0.5
COSIOTA 0.1
PSI 0.5
a pulsar in a binary system in a file called
J0404-0404.par
PSRJ J0404-0404
RAJ 04:04:00.0
DECJ -04:04:00.0
F0 1.93271605
F1 4.93827e-13
F2 -6.7067e-21
PEPOCH 55818.074666481479653
A1 1.4
ECC 0.09
OM 0.0
T0 55817.9830345370355644263
PB 0.1
BINARY BT
EPHEM DE405
UNITS TDB
H0 7.5e-25
PHI0 0.35
COSIOTA 0.6
PSI 1.1
One way to create the simulated data is as follows (where in this case we generate data with a very low level of simulated noise, so that the signals can be seen prominently):
#!/usr/bin/env python
import shutil
import subprocess as sp
from solar_system_ephemerides.paths import ephemeris_path
from cwinpy import PulsarParameters
# set data start, duration and bandwidth
fakedatastart = 1000000000
fakedataduration = 86400 # 1 day in seconds
fakedatabandwidth = 8 # 8 Hz
parfiles = ["J0123+0123.par", "J0404-0404.par"]
# create injection files for lalapps_Makefakedata_v5
# requirements for Makefakedata pulsar input files
isolatedstr = """\
Alpha = {alpha}
Delta = {delta}
Freq = {f0}
f1dot = {f1}
f2dot = {f2}
refTime = {pepoch}
h0 = {h0}
cosi = {cosi}
psi = {psi}
phi0 = {phi0}
"""
binarystr = """\
orbitasini = {asini}
orbitPeriod = {period}
orbitTp = {Tp}
orbitArgp = {argp}
orbitEcc = {ecc}
"""
injfile = "inj.dat"
fp = open(injfile, "w")
for i, parfile in enumerate(parfiles):
p = PulsarParameters(parfile)
fp.write("[Pulsar {}]\n".format(i + 1))
# set parameters (multiply freqs/phase by 2)
mfddic = {
"alpha": p["RAJ"],
"delta": p["DECJ"],
"f0": 2 * p["F0"],
"f1": 2 * p["F1"],
"f2": 2 * p["F2"],
"pepoch": p["PEPOCH"],
"h0": p["H0"],
"cosi": p["COSIOTA"],
"psi": p["PSI"],
"phi0": 2 * p["PHI0"],
}
fp.write(isolatedstr.format(**mfddic))
if p["BINARY"] is not None:
mfdbindic = {
"asini": p["A1"],
"Tp": p["T0"],
"period": p["PB"],
"argp": p["OM"],
"ecc": p["ECC"],
}
fp.write(binarystr.format(**mfdbindic))
fp.write("\n")
fp.close()
# set ephemeris files
efile = ephemeris_path(body="earth", jplde="DE405")
sfile = ephemeris_path(body="sun", jplde="DE405")
# set detector
detector = "H1"
channel = "{}:FAKE_DATA".format(detector)
# set noise amplitude spectral density (use a small value to see the signal
# clearly)
sqrtSn = 1e-29
# set Makefakedata commands
cmds = [
"-F",
".",
"--outFrChannels={}".format(channel),
"-I",
detector,
"--sqrtSX={0:.1e}".format(sqrtSn),
"-G",
str(fakedatastart),
"--duration={}".format(fakedataduration),
"--Band={}".format(fakedatabandwidth),
"--fmin",
"0",
'--injectionSources="{}"'.format(injfile),
"--outLabel=FAKEDATA",
'--ephemEarth="{}"'.format(efile),
'--ephemSun="{}"'.format(sfile),
]
# run makefakedata
sp.run([shutil.which("lalpulsar_Makefakedata_v5")] + cmds)
This should create the file H-H1_FAKEDATA-1000000000-86400.gwf in the gwf format.
Heterodyning the data#
We will show how to heterodyne the data in H-H1_FAKEDATA-1000000000-86400.gwf for the two
different pulsars by i) using a configuration file for the cwinpy_heterodyne executable, and ii)
using the Python API.
Using the executable#
For most inputs we will use the default values as described in the API for the
Heterodyne class, but otherwise we can set the heterodyne parameters via
a configuration file, in this case called example1_config.ini, containing:
# provide the GPS start and end times of the data to analyse
starttime = 1000000000
endtime = 1000086400
# set the "channel" within the frame file containing the strain data
channel = H1:FAKE_DATA
# set the detector from which the data
detector = H1
# set the frame file(s) to use
framecache = H-H1_FAKEDATA-1000000000-86400.gwf
# set the pulsar parameter files
pulsarfiles = [J0123+0123.par, J0404-0404.par]
# set the output directory for the heterodyned data
output = heterodyneddata
# HETERODYNE INPUTS
# set the resample rate in Hz
resamplerate = 0.016666666666666666
# low-pass filter filter knee frequency (more aggressive than the default of 0.5 Hz)
filterknee = 0.1
# include correcting for solar system and binary barycentring
includessb = True
includebsb = True
Running the cwinpy_heterodyne executable is done with:
cwinpy_heterodyne --config example1_config.ini
The outputs (HDF5 files containing HeterodynedData objects) will be placed in
the heterodyneddata directory as specified by the output option in the configuration file.
The default output file name format follows the convention
heterodyne_{pulsarname}_{detector}_{frequencyfactor}_{starttime}_{endtime}.hdf5. Therefore, the
above command creates the two files:
heterodyne_J0123+0123_H1_2_1000000000-1000086400.hdf5heterodyne_J0404-0404_H1_2_1000000000-1000086400.hdf5
We can now show the signals in the data, and compare them to purely simulated heterodyned data (the original frame files were created with code that is largely independent of CWInPy), with, e.g.:
from cwinpy import HeterodynedData
h1 = HeterodynedData.read("heterodyne_J0123+0123_H1_2_1000000000-1000086400.hdf5")
fig = h1.plot(which="both") # "both" specifies plotting real and imaginary data
# create simulated heterodyned signal purely with CWInPy
fakeh1 = HeterodynedData(
times=h1.times,
fakeasd=1e-48, # add very small amount of noise
detector="H1",
inject=True,
par=h1.par
)
ax = fig.gca()
ax.plot(fakeh1.times, fakeh1.data.real, "k--")
ax.plot(fakeh1.times, fakeh1.data.imag, "k--")
ax.set_title(h1.par["PSRJ"])
fig.tight_layout()
fig.show()
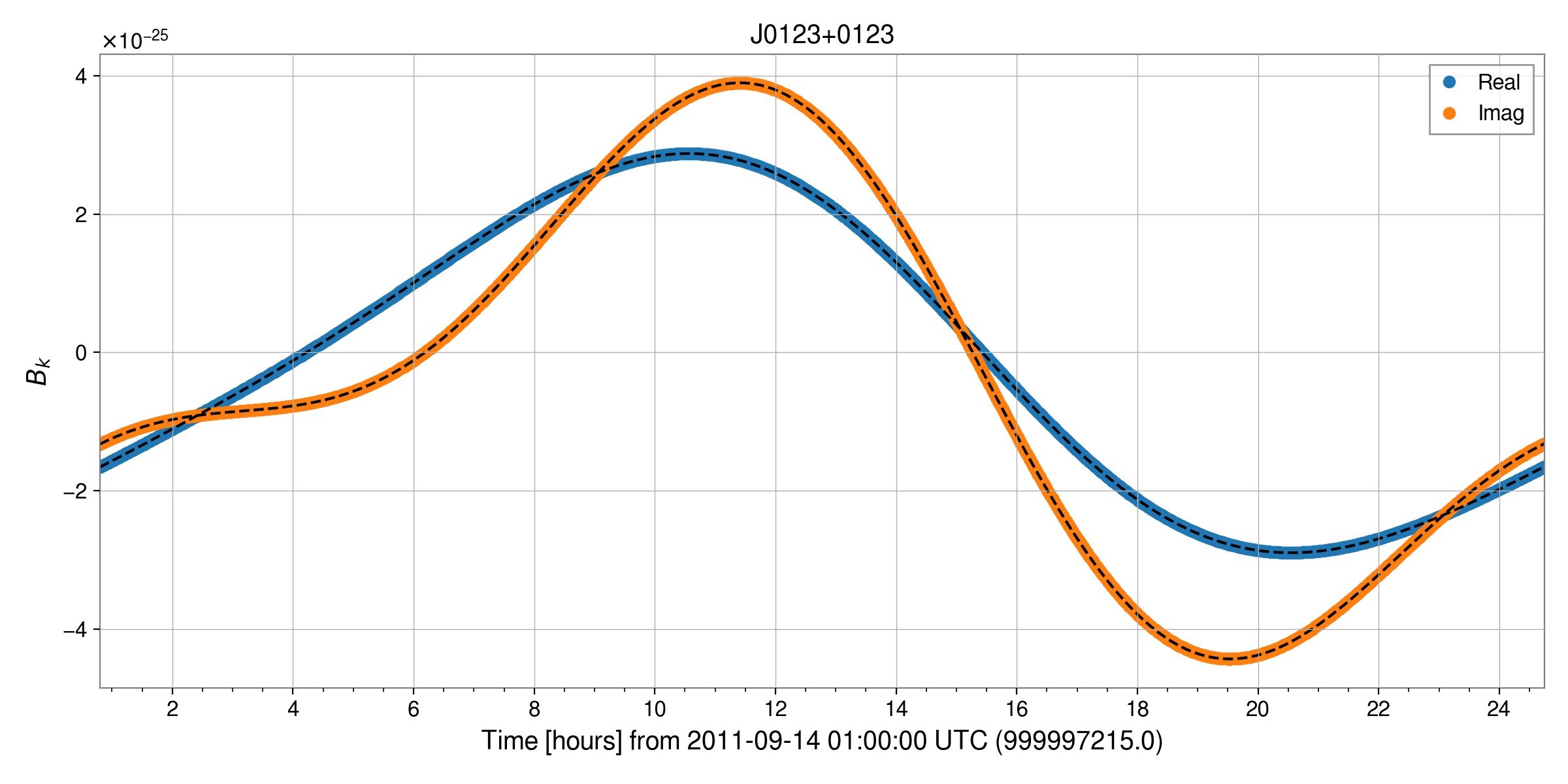
The coloured lines show the data as heterodyned from the frame data for J0123+0123, while the overplotted dashed lines show fake heterodyned signals produced by CWInPy.
Using the Python API#
There are two ways that the same thing can be achieved within Python via the API. Both use the
heterodyne() function, which is just a wrapper to the
Heterodyne class, but also runs the heterodyne via
cwinpy.heterodyne.Heterodyne.heterodyne().
The first option is to use a configuration file as above with:
from cwinpy.heterodyne import heterodyne
het = heterodyne(config="example1_config.ini")
The second way is to explicitly pass all the options as arguments, e.g.,
from cwinpy.heterodyne import heterodyne
het = heterodyne(
starttime=1000000000,
endtime=1000086400,
detector="H1",
channel="H1:FAKE_DATA",
framecache="H-H1_FAKEDATA-1000000000-86400.gwf",
pulsarfiles=["J0123+0123.par", "J0404-0404.par"],
output="heterodyneddata",
resamplerate=1.0 / 60.0,
includessb=True, # correct to solar system barycentre
includebsb=True, # correct to binary system barycentre
)
Using Tempo2 for phase calculation#
If you have the Tempo2 pulsar timing package and the libstempo Python wrapper for it installed, you can use it to generate the phase evolution used to heterodyne the data. This is achieved by including:
usetempo2 = True
in your configuration file, or as another keyword argument to the
heterodyne() function. The includeX keywords are not required in this
case and all delay corrections will be included.
Note
For signals from sources in binary systems there will be a phase offset between signals
heterodyned using the default LALSuite functions
and those heterodyned using Tempo2. This offset is not present for non-binary sources. In general
this is not problematic, but will mean that the if heterodyning data containing a simulated
binary signal created using, e.g., lalpulsar_Makefakedata_v5, the recovered initial phase will
not be consistent with the expected value.
Comparisons between heterodyning as described in the previous section and that using Tempo2 are shown below (the heterodyne using Tempo2 is shown as the black dashed lines):
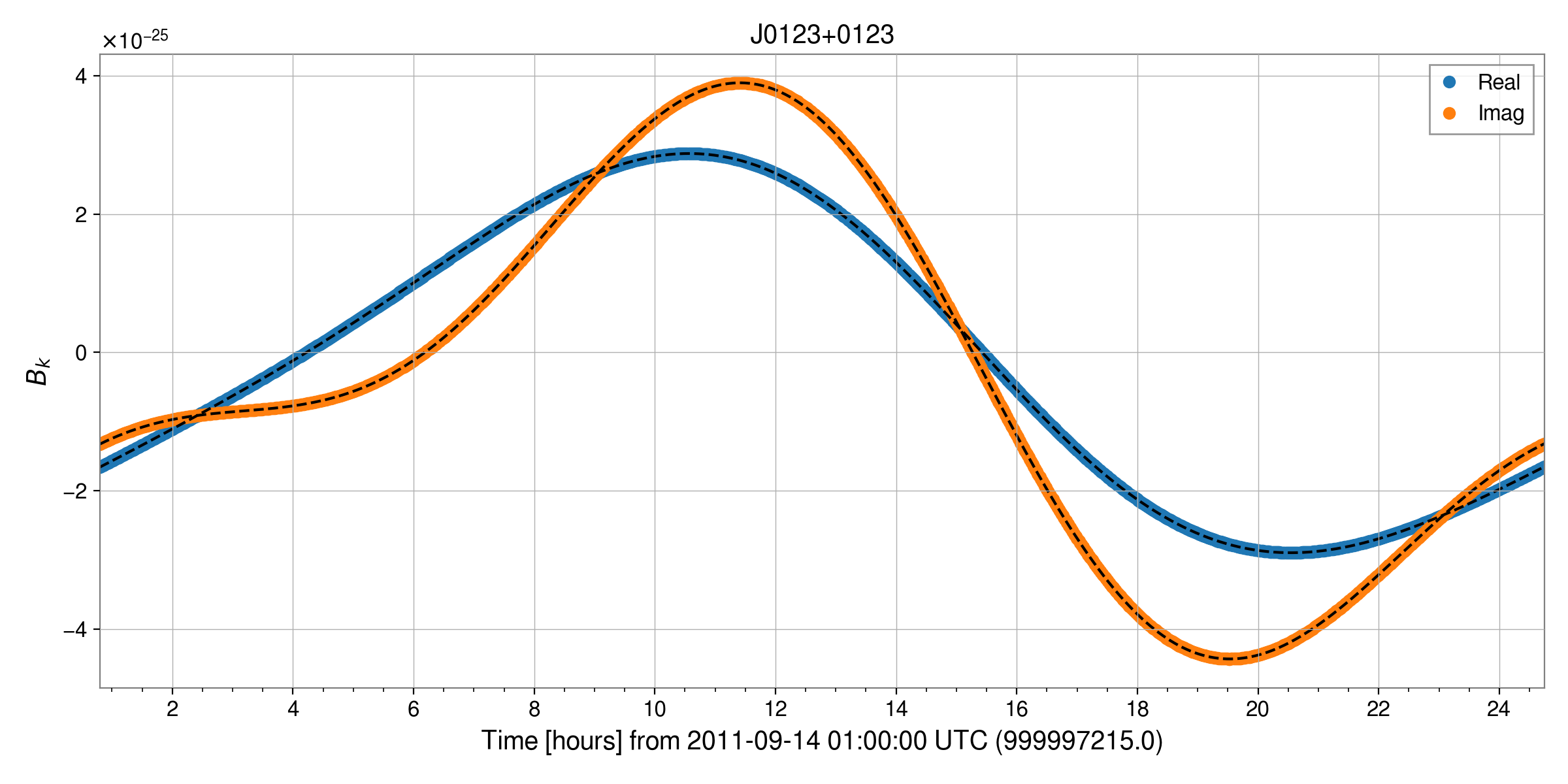
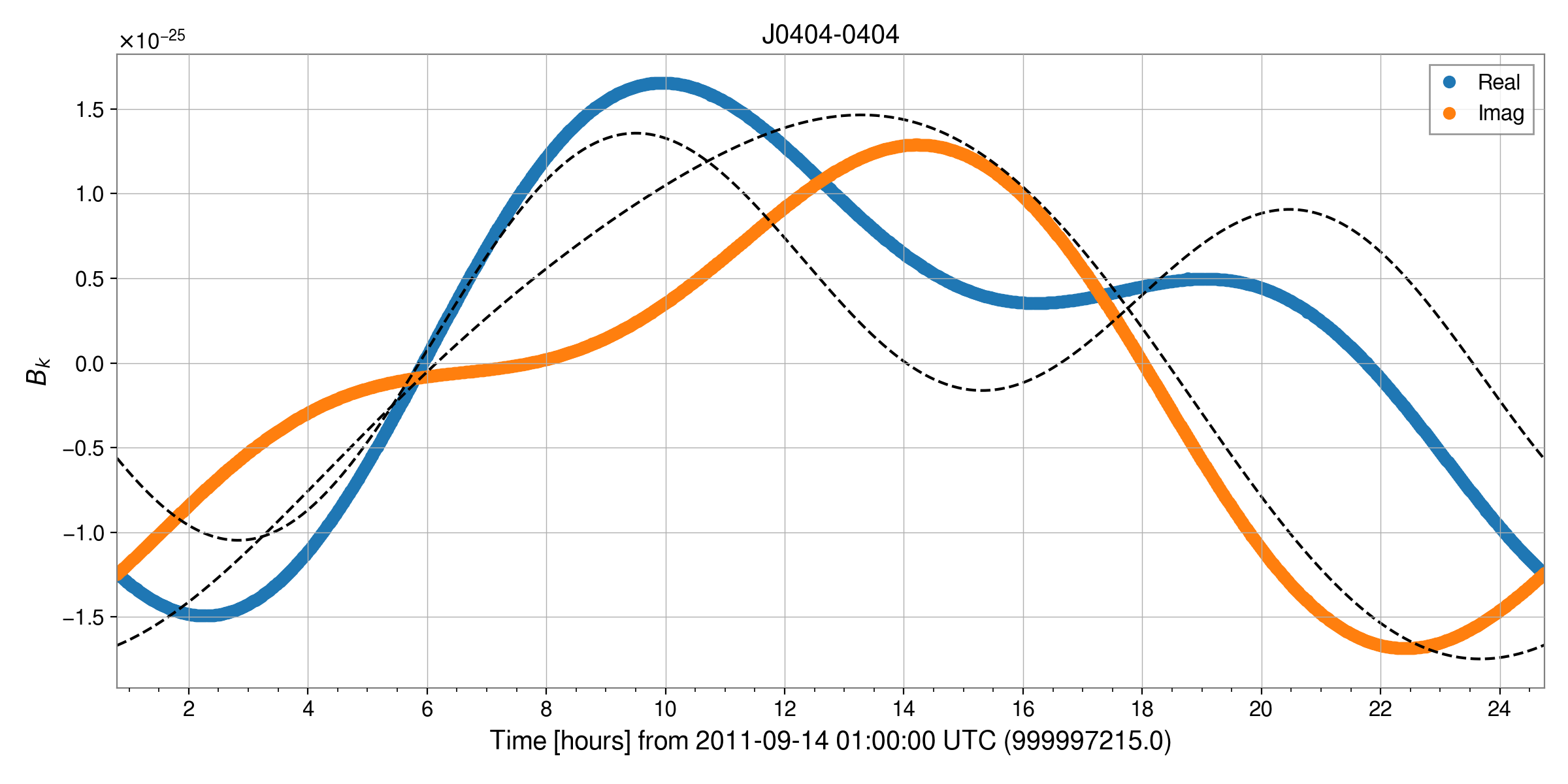
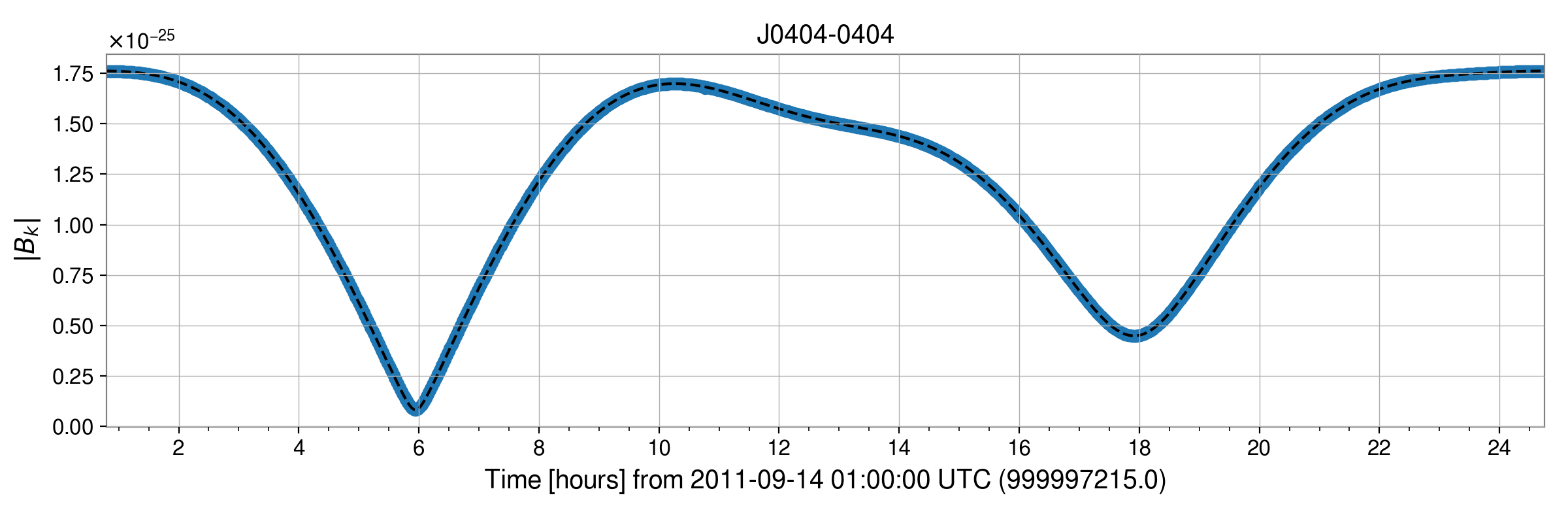
As noted there is a constant phase offset for the binary source J0404-0404, but the absolute value of the time series’ can be seen to be the same:
Example: hardware injections in LIGO O1 data#
In this example we will heterodyne the data for several hardware injection signals in LIGO Handford (H1) data during a day of the first observing run O1. This will require access to the data via CVMFS. The data time span will be from 1132478127 to 1132564527.
The example will look for the hardware injection signals 5 and 6 from the table here (note that the table
contains the gravitational-wave signal frequency and frequency derivative, which must be halved to
give equivalent “rotational” values in the parameter files). Files containing the parameters for all
these injections for each observing run are packaged with CWInPy with locations given in the
HW_INJ dictionary.
For this we can use the following configuration file:
# provide the GPS start and end times of the data to analyse
starttime = 1132478127
endtime = 1132564527
# set the "channel" within the frame files containing the strain data
channel = H1:LOSC-STRAIN
# set the detector from which the data
detector = H1
# set the base path of O1 frame files in CVMFS
framecache = /cvmfs/gwosc.osgstorage.org/gwdata/O1/strain.4k
# set the data science segments to include
includeflags = H1_DATA
# set the data segments to exclude (times with no injections)
excludeflags = H1_NO_CW_HW_INJ
# set the directory containing the pulsar parameter files
pulsarfiles = {hwinjpath}/O1
# set the names of the pulsars to include
pulsars = [JPULSAR05, JPULSAR06]
# set the output directory for the heterodyned data
output = heterodyneddata
# output the list of data segments used (optional)
outputsegmentlist = segments.txt
# output the list of frame data files that are generated (optional)
outputframecache = frames.txt
# set to resume heterodyning from where it left off, in case the job is
# interrupted
resume = True
# HETERODYNE INPUTS
# set the resample rate in Hz
resamplerate = 0.016666666666666666
# low-pass filter filter knee frequency (more aggressive than the default of 0.5 Hz)
filterknee = 0.1
# include correcting for solar system barycentring
includessb = True
In the above file the base CVMFS directory containing the strain data files has been specified,
which will be recursively searched for corresponding data. The includeflags and excludeflags
values have been used to set the valid time segments of data to use, with H1_DATA specifying
to use all available valid science quality data for the H1 detector, and H1_NO_CW_HW_INJ
specifying the exclusion of times when no continuous-wave hardware injections were being carried
out.
Running this analysis can then be achieved with the following code, where the first two lines just substitute the location of the parameter files into the configuration file:
basepath=`python -c "from cwinpy.info import HW_INJ_BASE_PATH; print(HW_INJ_BASE_PATH)"`
sed -i "s|{hwinjpath}|$basepath|g" example2_config.ini
cwinpy_heterodyne --config example2_config.ini
If the CVMFS data is being downloaded on-the-fly then (depending on your internet connection speed) this may take on the order of ten minutes to run.
The outputs (HDF5 files containing HeterodynedData objects) will be placed in
the heterodyneddata directory as specified by the output option in the configuration file.
The default output file name format follows the convention
heterodyne_{pulsarname}_{detector}_{frequencyfactor}_{starttime}_{endtime}.hdf5. Therefore, the
above command creates the two files:
heterodyne_JPULSAR05_H1_2_1132478127-1132564527.hdf5heterodyne_JPULSAR06_H1_2_1132478127-1132564527.hdf5
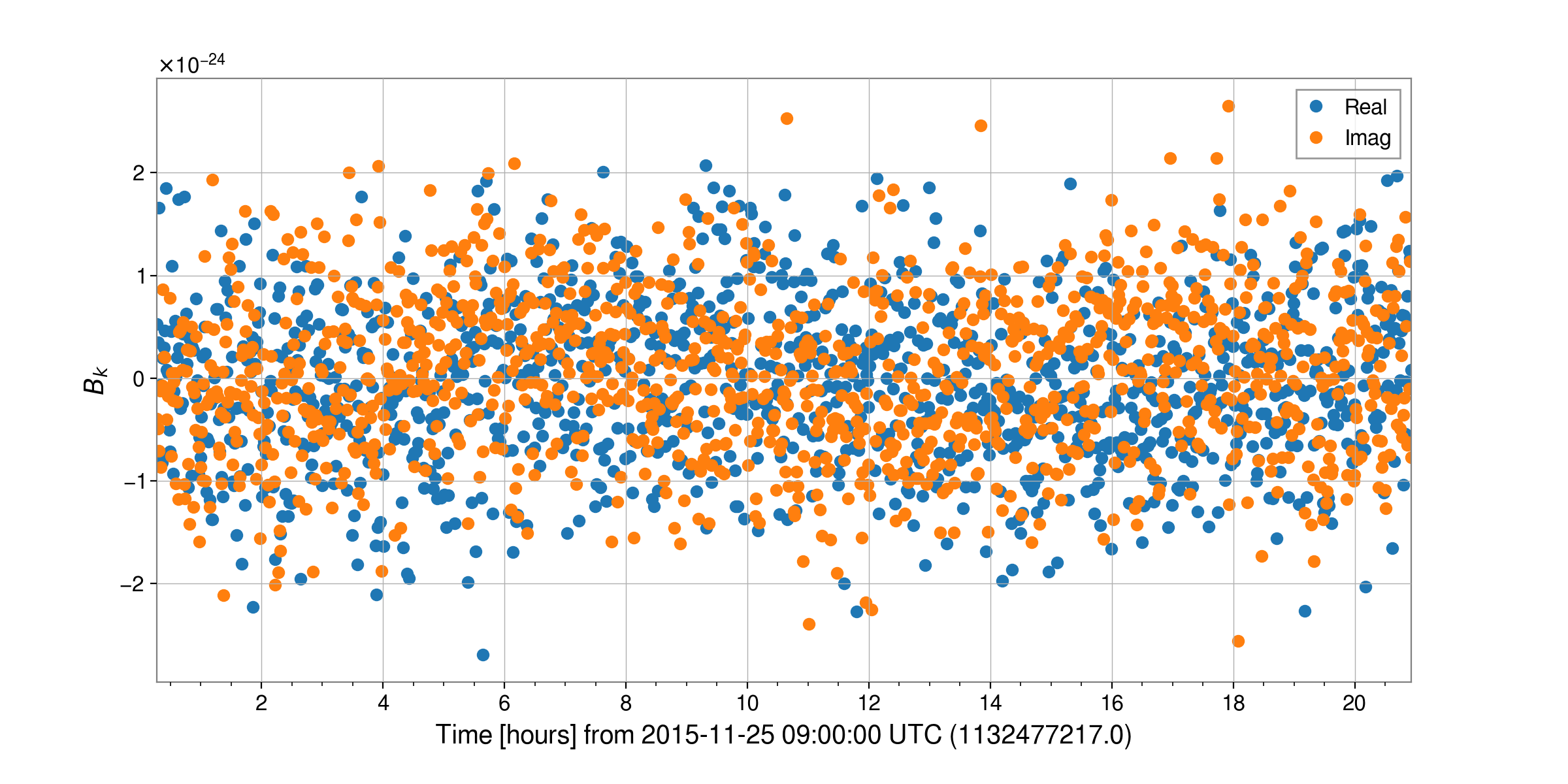
We can take a look at the heterodyned data for the hardware injection number 5 with:
from cwinpy import HeterodynedData
hwinj = HeterodynedData.read("heterodyne_JPULSAR05_H1_2_1132478127-1132564527.hdf5")
# "both" specifies plotting real and imaginary data, "remove_outliers" removes outliers!
fig = hwinj.plot(which="both", remove_outliers=True)
fig.show()
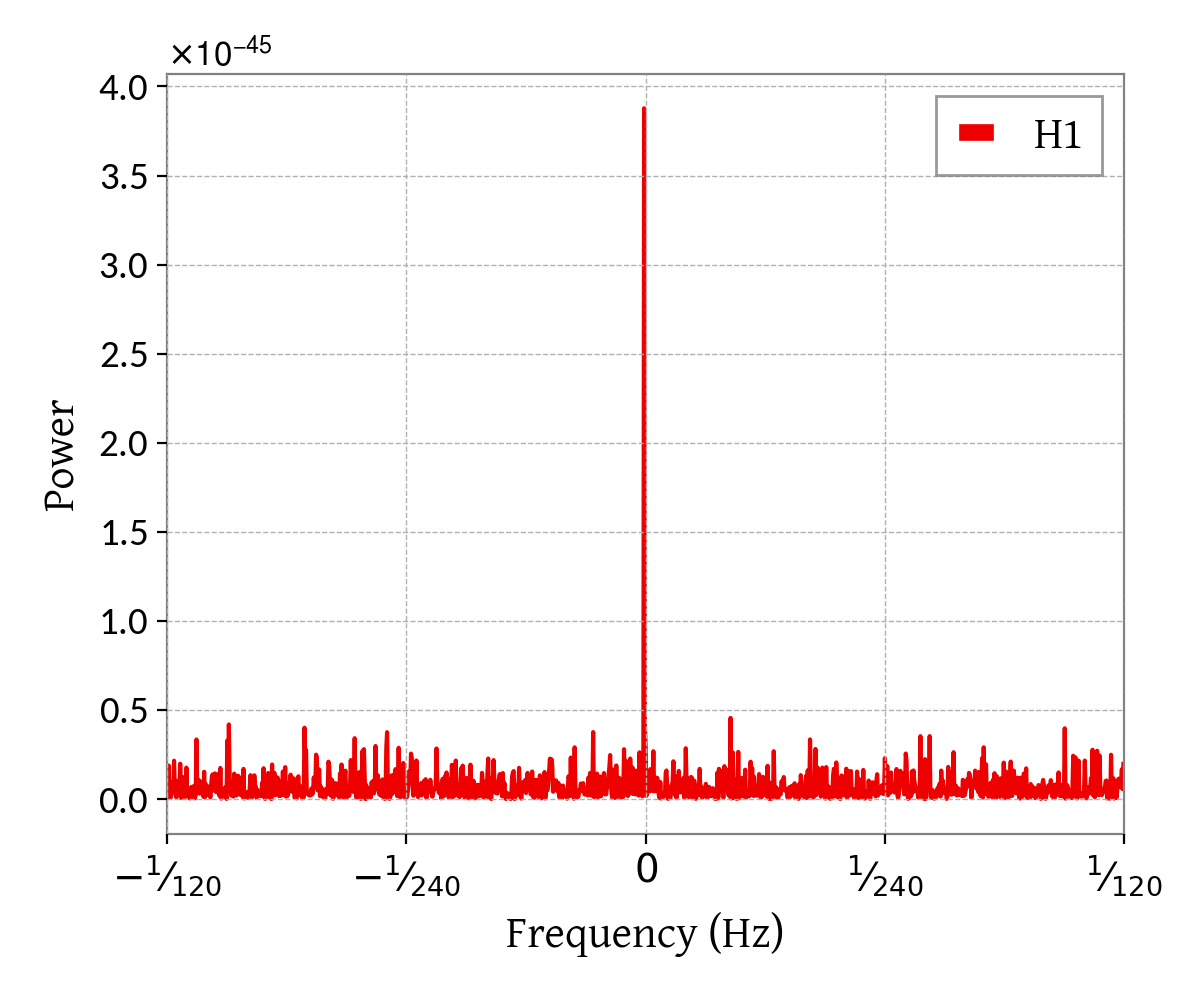
We can see the signal in the data by taking a spectrum:
figspec = hwinj.periodogram(remove_outliers=True)
figspec[-1].show()
If running on data spanning a whole observing run it makes sense to split up the analysis into many individual jobs and run them in parallel. This can be achieved by creating a HTCondor DAG, which can be run on a computer cluster (or on multiple cores on a single machine), as described below.
Example: two stage heterodyne#
As described in, e.g., [1], the heterodyne can be performed in two stages. For example, the first
stage could account for the signal’s phase evolution, but neglect Doppler and relativistic
solar/binary system effects while still low-pass filtering and heavily downsampling the data. The
second stage would then apply the solar/binary system effects at the lower sample rate. In the past,
with lalpulsar_heterodyne, this two stage approach provided speed advantages, although with
CWInPy that advantage is negligible. However, the two stage approach can be useful if you want to
analyse data with a preliminary source ephemeris, and then re-heterodyne the same data with an
updated source ephemeris. In most cases it is recommended to heterodyne in a single stage, which
also allows slightly more aggressive filtering to be applied.
To perform the run from the above example in
two stages one could use the following configuration (called, e.g., example3_stage1_config.ini)
file for stage 1:
# provide the GPS start and end times of the data to analyse
starttime = 1132478127
endtime = 1132564527
# set the "channel" within the frame files containing the strain data
channel = H1:LOSC-STRAIN
# set the detector from which the data
detector = H1
# set the base path of O1 frame files in CVMFS
framecache = /cvmfs/gwosc.osgstorage.org/gwdata/O1/strain.4k
# set the data science segments to include
includeflags = H1_DATA
# set the data segments to exclude (times with no injections)
excludeflags = H1_NO_CW_HW_INJ
# set the directory containing the pulsar parameter files
pulsarfiles = {hwinjpath}/O1
# set the names of the pulsars to include
pulsars = [JPULSAR05, JPULSAR06]
# set the output directory for the heterodyned data
output = heterodyneddata
# output the list of data segments used (optional)
outputsegmentlist = segments.txt
# output the list of frame data files that are generated (optional)
outputframecache = frames.txt
# set to resume heterodyning from where it left off, in case the job is
# interupted
resume = True
# HETERODYNE INPUTS
# initially resample to 1 Hz
resamplerate = 1.0
# do not correct for solar system barycentring
includessb = False
and then run the commands:
basepath=`python -c "from cwinpy.info import HW_INJ_BASE_PATH; print(HW_INJ_BASE_PATH)"`
sed -i "s|{hwinjpath}|$basepath|g" example3_stage1_config.ini
cwinpy_heterodyne --config example3_stage1_config.ini
The stage 2 configuration file (called, e.g, example3_stage2_config.ini) would then be:
# provide the GPS start and end times of the data to analyse
starttime = 1132478127
endtime = 1132564527
# set the "channel" within the frame files containing the strain data
channel = H1:LOSC-STRAIN
# set the detector from which the data
detector = H1
# set the base path of O1 frame files in CVMFS
framecache = /cvmfs/gwosc.osgstorage.org/gwdata/O1/strain.4k
# set the data science segments to include
includeflags = H1_DATA
# set the data segments to exclude (times with no injections)
excludeflags = H1_NO_CW_HW_INJ
# set the directory containing the pulsar parameter files
pulsarfiles = {hwinjpath}/O1
# set the names of the pulsars to include
pulsars = [JPULSAR05, JPULSAR06]
# set the directory containing the heterodyned data from stage 1
heterodyneddata = heterodyneddata
# set the output directory for the heterodyned data
output = heterodyneddata_stage2
# set to resume heterodyning from where it left off, in case the job is
# interrupted
resume = True
# HETERODYNE INPUTS
# initially resample to 1/60 Hz
resamplerate = 0.016666666666666666
# correct for solar system barycentring in this stage
includessb = True
which could be run with:
sed -i "s|{hwinjpath}|$basepath|g" example3_stage2_config.ini
cwinpy_heterodyne --config example3_stage2_config.ini
In this case the intermediate heterodyned data will be store in the heterodyneddata directory
and the final heterodyned data will be in the heterodyneddata_stage2 directory. We can plot
spectra of these outputs for comparison with, e.g.:
from matplotlib import pyplot as plt
from cwinpy import HeterodynedData
# read in stage 1 and stage 2 data
stage1 = HeterodynedData.read(
"heterodyneddata/heterodyne_JPULSAR05_H1_2_1132478127-1132564527.hdf5"
)
stage2 = HeterodynedData.read(
"heterodyneddata_stage2/heterodyne_JPULSAR05_H1_2_1132478127-1132564527.hdf5"
)
# create figure
fig, ax = plt.subplots(1, 2, figsize=(8,5))
# plot periodogram of the stage 1 data on the left
stage1.periodogram(remove_outliers=True, ax=ax[0])
ax[0].set_title("Stage 1 (full band)")
# plot zoom of stage 1 on the right
stage1.periodogram(remove_outliers=True, ax=ax[1], label="Stage 1 (zoom)")
# plot stage 2 over the zoom of stage 1
stage2.periodogram(remove_outliers=True, ax=ax[1], linestyle="--", color="g", label="Stage 2")
fig.show()
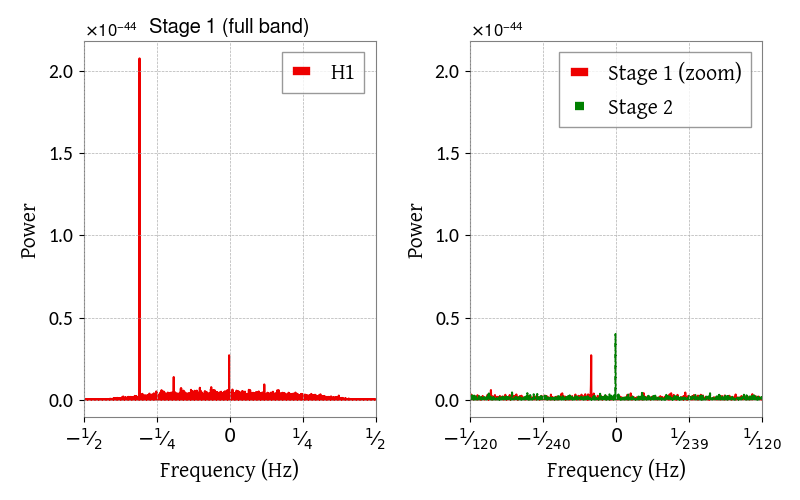
From the right panel it can be seen that the second stage of the heterodyne shifts the signal peak to approximately zero Hz, as expected, and increases the power in the peak, which will be slightly spread out over several frequency bins after only the first heterodyne stage.
Running using HTCondor#
When heterodyning long stretches of data it is preferable to split the observations up into more
manageable chunks of time. The can be achieved by splitting up the analysis and running it as
multiple independent jobs on a machine/cluster, or over the Open Science Grid, using the HTCondor
job scheduler system. This can be done using the cwinpy_heterodyne_pipeline executable (or the
heterodyne_pipeline() API).
This can be run using a configuration script containing the information as described in the example below:
[run]
# the base directory for the analysis **output**
basedir = /home/username/heterodyne
######### Condor DAG specific inputs ########
[heterodyne_dag]
# the location of the directory to contain the Condor DAG submission files
# (defaults to "basedir/submit")
;submit =
# the prefix of the name for the Condor DAGMan submit file (defaults to
# "dag_cwinpy_heterodyne"). "dag" will always be prepended.
;name =
# a flag specifying whether to automatically submit the DAG after its creation
# (defaults to False)
submitdag = False
# a flag saying whether to build the DAG (defaults to True)
;build =
# set whether running on the OSG (defaults to False). If using the OSG it
# expects you to be within an IGWN conda environment or using the singularity
# container option below.
;osg =
# if wanting to run on the OSG with the latest development version of cwinpy,
# which is within a Singularity container, set this flag to True
;singularity
# set whether Condor should transfer files to/from the local run node (default
# is "YES"). Note that if using "transfer_files" (or OSG above) all input files,
# e.g., pulsar parameter files, input frame cache files or segment files, or
# inputs of previously heterodyned data files, should have unique file names as
# when they are transferred there will be a flat directory structure.
;transfer_files =
# a flag saying whether to use SciTokens for authentication when getting
# proprietary frames over CVMFS. Default is False.
;use_scitokens =
# if running on the OSG you can select desired sites to run on
# see https://computing.docs.ligo.org/guide/condor/submission/#DESIRED_Sites
;desired_sites =
;undesired_sites =
######## cwinpy_heterodyne Job options ########
[heterodyne_job]
# the location of the cwinpy_heterodyne executable to use (defaults to try and
# find cwinpy_heterodyne in the current user PATH)
;executable =
# set the Condor universe (defaults to "vanilla")
;universe =
# directory location for the output from stdout from the Job (defaults to
# "basedir/log")
;out =
# directory location for the output from stderr from the Job (defaults to
# "basedir/log")
;error =
# directory location for any logging information from the jobs (defaults to
# "basedir/log")
;log =
# the location of the directory to contain the Condor job submission files
# (defaults to "basedir/submit")
;submit =
# the amount of available memory request for each job (defaults to 16 Gb)
# [Note: this is required for vanilla jobs on LIGO Scientific Collaboration
# computer clusters]
;request_memory =
# the amount of disk space required for each job (defaults to 2 Gb)
# [Note: this is required for vanilla jobs on LIGO Scientific Collaboration
# computer clusters]
;request_disk =
# the number of CPUs the job requires (defaults to 1, cwinpy_heterodyne is not
# currently parallelised in any way)
;request_cpus =
# additional Condor job requirements (defaults to None)
;requirements =
# set how many times the DAG will retry a job on failure (default to 2)
;retry =
# Job accounting group and user [Note: these are required on LIGO Scientific
# Collaboration computer clusters, but may otherwise be left out, see
# https://accounting.ligo.org/user for details of valid accounting tags
;accounting_group =
accounting_group_user = albert.einstein
[ephemerides]
# This specifies the pulsar parameter files for which to heterodyne the data.
# It can be either:
# - a string giving the path to an individual pulsar TEMPO(2)-style parameter
# file
# - a string giving the path to a directory containing multiple TEMPO(2)-style
# parameter files (the path will be recursively searched for any file with
# the extension ".par")
# - a list of paths to individual pulsar parameter files
# - a dictionary containing paths to individual pulsars parameter files keyed
# to their names.
# If instead, pulsar names are given rather than parameter files it will
# attempt to extract an ephemeris for those pulsars from the ATNF pulsar
# catalogue. If such ephemerides are available then they will be used
# (notification will be given when this is these cases).
pulsarfiles = /home/username/pulsars
# If checking the ATNF pulsar catalogue for pulsars, the version of the
# catalogue can be set. By default, the latest version will be used.
;atnf-version = latest
# You can analyse only particular pulsars from those specified by parameter
# files found through the "pulsarfiles" argument by passing a string, or list
# of strings, with particular pulsars names to use.
;pulsars =
# Locations of the Earth and Sun ephemerides. If not given then the ephemerides
# will be automatically determined from the pulsar parameter information. The
# values should be dictionaries keyed to the ephemeris type, e.g., "DE405", and
# pointing to the location of the ephemeris file.
;earth =
;sun =
######## heterodyne specific options ########
[heterodyne]
# A list of the prefix names of the set of gravitational wave detectors to use.
# If only one detector is being used it does not need to be given as a list.
detectors = ["H1", "L1"]
# A list, or single value, with the frequency scale factors at which to
# heterodyne the data. By default this will have a value of 2, i.e., heterodyne
# at twice the pulsar's rotation frequency
;freqfactors =
# A dictionary containing the start times of the data to use for each detector.
# These start times can be lists if multiple different datasets are being used,
# e.g., O1 and O2, where different channel names or DQ flags might be required.
# If a single value is given it is used for all detectors.
starttimes = {"H1": [1125969918, 1164556817], "L1": [1126031358, 1164556817]}
# A dictionary containing the end times of the data to use for each detector.
# These end times can be lists if multiple different datasets are being used,
# e.g., O1 and O2, where different channel names or DQ flags might be required.
# If a single value is given it is used for all detectors.
endtimes = {"H1": [1137258494, 1187733618], "L1": [1137258494, 1187733618]}
# The length of time in integer seconds to "stride" through the data, i.e.,
# read-in and heterodyne in one go. Default is 3600 seconds.
;stride =
# The (on average) length of data (in seconds) for which to split into
# individual (coarse or one-stage) heterodyning jobs for a particular detector
# and frequency factor. Default is 86400, i.e., use a days worth data for each
# job. If wanting to just have a single job for all data then set this to 0.
joblength = 86400
# The number of jobs over which to split up the (coarse or one-stage)
# heterodyning over pulsars for a particular detector and frequency factor.
# Default is 1. Use this to prevent too many files being required to be
# transferred if running over the OSG.
;npulsarjobs =
# The frame "types" to search for containing the required strain data. This
# should be a dictionary, keyed to detector names (with the same names as in
# the detectors list and starttimes/endtimes dictionaries). For each detector
# there should be a single frame type, or if multiple start times and end times
# are given there should be a list of frame types for each time segment (i.e.,
# different frame types for different observing runs). Alternatively, frame
# cache files (or lists of frame cache files for different time spans) can be
# provided using the framecache value below, which contain pre-made lists of
# frame files.
frametypes = {"H1": ["H1_HOFT_C02", "H1_CLEANED_HOFT_C02"], "L1": ["L1_HOFT_C02", "L1_CLEANED_HOFT_C02"]}
# If you have a pre-generated cache of frame files for each detector, or the
# path to a directory that contains frames files (they can be found recursively
# within sub-directories of the supplied directory), they can be supplied
# instead of (or with, if suppling a directory) the frametypes option. This
# should be in the form of a dictionary and keyed to the detector names. If
# there are multiple start times each dictionary item can be a list containing
# a file for that given time segment.
;framecaches =
# This specficies the channels with the gravitational-wave frame files from
# which to extract the strain data. This should be in the form of a dictionary
# and keyed to the detector names. If there are multiple start times each
# dictionary item can be a list containing the channel for that given time
# segment.
channels = {"H1": ["H1:DCS-CALIB_STRAIN_C02", "H1:DCH-CLEAN_STRAIN_C02"], "L1": ["L1:DCS-CALIB_STRAIN_C02", "L1:DCH-CLEAN_STRAIN_C02"]}
# This specifies whether to strictly require that all frame files that are
# requested are able to be read in, otherwise an exception is raised. This
# defaults to False, allowing corrupt/missing frame files to be ignored.
;strictdatarequirement =
# This specifies the server name used to find the frame information if
# using the frametypes option. E.g., use https://gwosc.org for
# open data direct from GWOSC, or datafind.gwosc.org for open data via
# CVMFS. LVK collaboration members can use datafind.ligo.org:443 to find data.
host = datafind.ligo.org:443
# This specifies the server name used to find data quality segment information.
# By default this will use the server https://segments.ligo.org if nothing is
# given and the segmentlist option below is not used.
;segmentserver =
# If querying the segment server the date segment to use are specified by the
# flags that you want to include. This should be a dictionary, keyed to the
# detector name (with the same names as in the detectors list and
# starttimes/endtimes dictionaries). For each detector there should be a single
# data quality flag name, or if multiple start and end times are given there
# should be a list of data quality flags for each segment.
includeflags = {"H1": ["H1:DCS-ANALYSIS_READY_C02", "H1:DCH-CLEAN_SCIENCE_C02:1"], "L1": ["L1:DCS-ANALYSIS_READY_C02", "L1:DCH-CLEAN_SCIENCE_C02:1"]}
# Data quality segments to exclude from analysis can also be set. This should
# be a dictionary keyed to the detector names. For each detector multiple
# exclusion flags can be used. If there are multiple start and end times the
# exclusion flags for each segment should be given in a list, and within the
# list multiple flags for the same segment should be separated by commas. If no
# exclusions are required for a given segment then an empty string should be
# given.
excludeflags = {"H1": ["H1:DCS-BAD_STRAIN_H1_HOFT_C02:1,H1:DCS-BAD_KAPPA_BASIC_CUT_H1_HOFT_C02:1", ""], "L1": ["L1:DCS-BAD_KAPPA_BASIC_CUT_L1_HOFT_C02:1", ""]}
# Rather than having the pipeline produce the segment lists, pre-generated
# segment list files can be passed to the code. This should be given as a
# dictionary keyed to the detector names. For each detector a file containing
# the segments (plain ascii text with two columns giving the start and end of
# each segment) should be given, or for multiple start and end times, lists of
# files can be given.
;segmentlists =
# Set whether the heterodyne in performed in one stage (set to 1) or two
# stages, the so-called "coarse" and "fine" heterodyne (set to 2). Default is
# to use one stage.
;stages =
# The rate at which to resample the data. If performing the heterodyne in one
# stage this should be a single value, if performing it in two stages it should
# be a list with the first value being the resample rate for the first stage
# and the second being the resample rate for the second stage. By default, the
# final sample rate in either case is 1/60 Hz, and for a two stage process the
# first resample rate of 1 Hz.
;resamplerate =
# The knee frequency (Hz) of the low-pass filter applied after heterodyning the
# data. This should only be given when heterodying raw strain data and not if
# re-heterodyning processed data. Default is 0.1 Hz is heterodyning in one
# stage and 0.5 Hz if heterodyning over two stages.
;filterknee =
# The order of the low-pass Butterworth filter applied after heterodyning the
# data. The default is 9.
;filterorder =
# The number of seconds to crop from the start and end of data segments after
# the initial heterodyned to remove filter impulse effects and issues prior to
# lock-loss. Default is 60 seconds.
;crop =
# The location of previously heterodyned data files for input. This should be a
# string or dictionary of strings containing the full file path, or directory
# path, pointing the the location of pre-heterodyned data. For a single pulsar
# a file path can be given. For multiple pulsars a directory containing
# heterodyned files (in HDF5 or txt format) can be given provided that within
# it the file names contain the pulsar names as supplied in the file input with
# pulsarfiles. Alternatively, a dictionary can be supplied, keyed on the pulsar
# name, containing a single file path, a directory path as above, or a list of
# files/directories for that pulsar. If supplying a directory, it can contain
# multiple heterodyned files for a each pulsar and all will be used.
;heterodyneddata =
# The directory location to output the heterodyned data files. If performing
# the heterodyne in one stage this should be a single string containing the
# name of the directory to output data to (which will be created if it does not
# exist), or a dictionary keyed by detector name pointing to output directories
# for each detector. If performing the heterodyne in two stages this should be
# a list containing two items, each of which would be consistent with the above
# information.
outputdir = {"H1": "/home/username/heterodyne/H1", "L1": "/home/username/heterodyne/L1"}
# A label used for the output filename. If performing the heterodyne in one
# stage this can be a single value, or for two stages can be a list with an
# item for the value to use for each stage. By default the label naming
# convention follows:
# heterodyne_{psr}_{det}_{freqfactor}_{gpsstart}-{gpsend}.hdf5
# where the keys are used to based on the analysis values. These keys can be
# used in alternative labels.
;label =
# A flag to set whether to correct the signal to the solar system barycentre.
# For a one stage heterodyne this should just be a boolean value (defaulting to
# True). For a two stage heterodyne it should be a list containing a boolean
# value for the coarse stage and the fine stage (defaulting to [False, True]).
includessb = True
# A flag to set whether to correct the signal to the binary system barycentre
# if required. See includessb for the format and defaults.
includebsb = True
# A flag to set whether to correct the signal for any glitch induced phase
# evolution if required. See includessb for the format and defaults.
includeglitch = True
# A flag to set whether to correct the signal for any sinusoidal WAVES
# parameters used to model timing noise if required. See includessb for the
# format and defaults.
includefitwaves = True
# If performing the full heterodyne in one step it is quicker to interpolate
# the solar system barycentre time delay and binary barycentre time delay. This
# sets the step size, in seconds, between the points in these calculations that
# will be the interpolation nodes. The default is 60 seconds.
;interpolationstep =
# The pulsar timing package TEMPO2 can be used to calculate the pulsar phase
# evolution rather than the LAL functions. To do this set the flag to True.
# TEMPO2 and the libstempo package must be installed. This can only be used if
# performing the heterodyne as a single stage. The solar system ephemeris files
# and include... flags will be ignored. All components of the signal model
# (e.g., binary motion or glitches) will be included in the phase generation.
;usetempo2 =
# Set this flag to make sure any previously generated heterodyned files are
# overwritten. By default the analysis will "resume" from where it left off,
# such as after forced Condor eviction for checkpointing purposes. Therefore,
# this flag is needs to be explicitly set to True (the default is False) if
# not wanting to use resume.
;overwrite =
######## options for merging heterodyned files ########
[merge]
# Merge multiple heterodyned files into one. The default is True
;merge =
# Overwrite existing merged file. The default is True
;overwrite =
# Remove inidividual pre-merged files. The default is False.
remove = True
where this contains information for heterodyning data from the O1 and O2 observing runs for the
two LIGO detectors, H1 and L1. Comments about each input parameter, and different potential input
options are given inline; some input parameters are also commented out using a ; in which case
the default values would be used. For more information on the various HTCondor options see the user
manual.
This configuration file could then be run to generate the HTCondor DAG using:
cwinpy_heterodyne_pipeline cwinpy_heterodyne_pipeline.ini
and the generated DAG then submitted (if the submitdag option is set to False in the
configuration file) using:
condor_submit_dag /home/username/heterodyne/submit/dag_cwinpy_heterodyne.submit
This example will generate the following directory tree structure:
/home/username/heterodyne
├── configs # directory containing configuration files for individual cwinpy_heterodyne runs
├── submit # directory containing the Condor submit and DAG files
├── log # directory containing the Condor log files
├── H1 # directory containing the heterodyned data files for the H1 detector
└── L1 # directory containing the heterodyned data files for the L1 detector
By default, the multiple heterodyned data files for each pulsar created due to the splitting will be
merged using the cwinpy_heterodyne_merge executable (see the
heterodyne_merge() API). If the remove option is set in the
configuration file then the individual unmerged files will be removed, but by default they will be
kept (although not for the Quick setup).
The default naming format of the output heterodyned data files in their respective detector
directories will be:
heterodyne_{pulsarname}_{detector}_{frequencyfactor}_{gpsstart}-{gpsend}.hdf5 although this can
be altered using the label option (it is recommended to stick to the default for consistency).
Note
If running on IGWN grid computing clusters the accounting_group value must
be specified and provide a valid tag. Valid tag names can be found here unless custom values for a specific cluster are allowed.
As stated earlier, if accessing proprietary LIGO/Virgo data on a cluster you will need to make sure to run:
htgettoken --audience https://datafind.ligo.org --scope gwdatafind.read -a vault.ligo.org --issuer igwn
to generate a SciToken, before running the executable.
Two stage approach#
As described in Example: two stage heterodyne, the heterodyne can be run in two stages with, for example, the first stage taking account of the phase evolution while ignoring Doppler/relativistic effects, and the second stage subsequently including these effects. While it is recommended to perform the heterodyne in a single stage, it may sometimes be useful to have intermediate products.
To create a DAG for this “two stage” approach, the following option needs to be set in the
[heterodyne] section of the configuration file:
[heterodyne]
stages = 2
The resamplerate option can then be given as a list containing two values: the resample rates for
each stage. If not given, the default is to resample to 1 Hz for the first stage and 1/60 Hz for the
second stage. The values in the dictionary given for the outputdir option should also be lists
of two directories where the outputs of each stage will be located. The options includessb,
includebsb, includeglitch and includefitwaves should also be two-valued lists of
booleans stating which phase model components to include in each stage. By default, the first stage
will have these all as False and the second stage will have them all as True.
Note
By default, if running the the two stage approach, the knee frequency of the low-pass filter will
be 0.5 Hz compared to 0.1 Hz if running a single stage. This differs from the default used by
lalpulsar_heterodyne, which uses 0.25 Hz.
Re-heterodyning data#
If you have previously heterodyned data files that you want to re-heterodyne (these might be the
outputs of the first stage of a two stage analysis) then you can use the configuration file with the
stages option set to 1, but instead supply the heterodyneddata option in the
[heterodyne] section rather than frame information. This can be a path to a directory containing
previously heterodyned data (HeterodynedData objects saved in HDF5 format), an
individual file path (if analysing a single pulsar), or a dictionary keyed to the pulsar name and
pointing to the heterodyned data path for that source.
Quick setup#
The cwinpy_heterodyne_pipeline script has some quick setup options that allow an analysis to be
launched in one line without the need to define a configuration file. These options require that
the machine/cluster that you are running HTCondor on has access to open data from GWOSC available
via CVMFS. It is also recommended that you run CWInPy from within an IGWN conda environment
For example, if you have a Tempo(2)-style pulsar parameter file, e.g., J0740+6620.par, and you
want to analyse the open O1 data for the two LIGO detectors
you can simply run:
cwinpy_heterodyne_pipeline --run O1 --pulsar J0740+6620.par --output /home/usr/heterodyneddata
where /home/usr/heterodyneddata is the name of the directory where the run information and
results will be stored (if you don’t specify an --output then the current working directory will
be used). This command will automatically submit the HTCondor DAG for the job. To specify multiple
pulsars you can use the --pulsar option multiple times. If you do not have a parameter file for
a pulsar you can instead use the ephemeris given by the ATNF pulsar catalogue. To do this you need to instead supply a
pulsar name (as recognised by the catalogue), for example, to run the analysis using O2 data for the
pulsar J0737-3039A you could do:
cwinpy_heterodyne_pipeline --run O2 --pulsar J0737-3039A --output /home/usr/heterodyneddata
Internally, the ephemeris information is obtained using the QueryATNF class
from psrqpy.
Note
Any pulsar parameter files extracted from the ATNF pulsar catalogue will be held in a
subdirectory of the directory from which you invoked the cwinpy_knope_pipeline script, called
atnf_pulsars. If such a directory already exists and contains the parameter file for a
requested pulsar, then that file will be used rather than being reacquired from the catalogue. To
ensure files are up-to-date, clear out the atnf_pulsars directory as required.
CWInPy also contains information on the continuous hardware injections performed in each run, so if you wanted the analyse the these in, say, the LIGO sixth science run, you could do:
cwinpy_heterodyne_pipeline --run S6 --hwinj --output /home/usr/hwinjections
Other command line arguments for cwinpy_heterodyne_pipeline, e.g., for setting specific detectors,
can be found below. If running on a LIGO Scientific
Collaboration cluster the --accounting-group flag must be set to a valid accounting tag, e.g.,:
cwinpy_heterodyne_pipeline --run O1 --hwinj --output /home/user/O1injections --accounting-group ligo.prod.o1.cw.targeted.bayesian
Note
The quick setup will only be able to use default parameter values for the heterodyne. For “production” analyses, or if you want more control over the parameters, it is recommended that you use a configuration file to set up the run.
The frame data used by the quick setup defaults to that with a 4096 Hz sample rate. However, if
analysing sources with frequencies above about 1.6 kHz this should be switched, using the
--samplerate flag, to using the 16 kHz sampled data. By default, if analysing hardware
injections for any of the advanced detector runs the 16 kHz data will be used due to frequency of
the fastest pulsar being above 1.6 kHz.
Command line arguments#
The command line arguments for cwinpy_heterodyne can be found using:
$ cwinpy_heterodyne --help
Traceback (most recent call last):
File "/home/docs/checkouts/readthedocs.org/user_builds/cwinpy/conda/latest/bin/cwinpy_heterodyne", line 3, in <module>
from cwinpy.heterodyne.heterodyne import heterodyne_cli
File "/home/docs/checkouts/readthedocs.org/user_builds/cwinpy/conda/latest/lib/python3.12/site-packages/cwinpy/heterodyne/__init__.py", line 2, in <module>
from .heterodyne import heterodyne, heterodyne_merge, heterodyne_pipeline
File "/home/docs/checkouts/readthedocs.org/user_builds/cwinpy/conda/latest/lib/python3.12/site-packages/cwinpy/heterodyne/heterodyne.py", line 19, in <module>
from htcondor.dags import DAG, write_dag
ModuleNotFoundError: No module named 'htcondor'
The command line arguments for cwinpy_heterodyne_pipeline can be found using:
$ cwinpy_heterodyne_pipeline --help
Traceback (most recent call last):
File "/home/docs/checkouts/readthedocs.org/user_builds/cwinpy/conda/latest/bin/cwinpy_heterodyne_pipeline", line 3, in <module>
from cwinpy.heterodyne.heterodyne import heterodyne_pipeline_cli
File "/home/docs/checkouts/readthedocs.org/user_builds/cwinpy/conda/latest/lib/python3.12/site-packages/cwinpy/heterodyne/__init__.py", line 2, in <module>
from .heterodyne import heterodyne, heterodyne_merge, heterodyne_pipeline
File "/home/docs/checkouts/readthedocs.org/user_builds/cwinpy/conda/latest/lib/python3.12/site-packages/cwinpy/heterodyne/heterodyne.py", line 19, in <module>
from htcondor.dags import DAG, write_dag
ModuleNotFoundError: No module named 'htcondor'