Known pulsar parameter estimation#
CWInPy can be used for perform Bayesian inference on gravitational-wave data to estimate the gravitational-wave signal parameters for emission from a known pulsar. To sample from the joint parameter posterior distributions, CWInPy uses the bilby package as an interface to a variety of stochastic sampling methods.
CWInPy comes with an executable, cwinpy_pe, for performing this analysis, which tries to
emulate, as much as possible, the functionality from the LALSuite code lalpulsar_parameter_estimation_nested (formerly
lalapps_pulsar_parameter_estimation_nested) described in [1].
There is also an API for running this analysis from within a Python shell or script as described below.
Running the analysis#
The cwinpy_pe executable, and API, can be used to perform
parameter estimation over a variety of signal parameter both on real data or simulated data. We will
cover some examples of both cases and show equivalent ways of running the analysis via the use of:
command line arguments to the cwinpy_pe executable, a configuration file, or the
API. The current command line arguments for cwinpy_pe are given
below.
Example: single detector data#
In the first example we will show how to perform parameter estimation on some real
gravitational-wave data. We will use a short segment of data from the O1 run of the LIGO detectors
(the whole of which can be found on the GWOSC website) between GPS times of 1132444817 and 1136419217. The
O1 dataset contains a set of simulated pulsar signals that have been “injected” into it. We will look at the injected signal named
PULSAR8, the parameters of which can be found at this link.
The data we will use in this example is from the LIGO Hanford
detector (abbreviated to “H1”) and has been heterodyned using the known phase evolution of the
simulated signal (see the description here), and low-pass filtered and
down-sampled to a rate of one sample per minute. This data file (in a gzipped format) can be
downloaded here: fine-H1-PULSAR08.txt.gz.
A Tempo(2)-style [2] pulsar parameter (.par) file for this simulated signal is reproduced below
and can be downloaded here, where it should be noted that the F0
and F1 parameters in that file are the expected rotation frequency and frequency derivative
of the putative pulsar, so they are half those of the simulated gravitational-wave signal in the
data.
NAME JPULSAR08
PSRJ JPULSAR08
F0 97.15415925
F1 -4.325e-09
RAJ 23:25:33.4997197871
DECJ -33:25:06.6608320859
PEPOCH 52944.0007428703684126958
UNITS TDB
H0 1.10013760155e-24
PSI 0.170470927
PHI0 2.945
COSIOTA 0.073902656035643471
Here we will try and estimate four of the signal’s parameters: the gravitational-wave amplitude
\(h_0\); the inclination angle \(\iota\) of the rotation axis to the line-of-sight; the
initial rotational phase of the signal \(\phi_0\); and the polarisation angle of the source
\(\psi\). To do this we have to define a file containing the prior probability distributions for
these parameters. We can define the priors in a file as described in the documentation for the
bilby package, which is reproduced below and can
be downloaded here:
# define priors on: the gravitational-wave amplitude, inclination angle,
# initial phase and polarisation angle
h0 = Uniform(name='h0', minimum=0, maximum=1e-22, latex_label='$h_0$')
iota = Sine(name='iota', minimum=0., maximum=np.pi, latex_label='$\iota$', unit='rad')
phi0 = Uniform(name='phi0', minimum=0, maximum=np.pi, latex_label='$\phi_0$', unit='rad')
psi = Uniform(name='psi', minimum=0, maximum=np.pi / 2, latex_label='$\psi$', unit='rad')
Here we have set the prior on \(h_0\) to be uniform between 0 and 10-22, where in this case the maximum has been chosen to be large compared to the expected signal strength. The combination of the \(\iota\) and \(\psi\) parameters has been chosen to be uniform over a sphere, which means using a uniform prior over \(\psi\) between 0 and \(\pi/2\) (there is a degeneracy meaning this doesn’t have to cover the full range between 0 and \(2\pi\) [1] [3]), and a sine distribution prior on \(\iota\) (equivalently one could use a uniform prior on a \(\cos{\iota}\) parameter between -1 and 1). The \(\phi_0\) parameter is the initial rotational phase at a given epoch, so only needs to span 0 to \(\pi\) to cover the full phase of the equivalent gravitational-wave phase parameter in the case where the source is emitting at twice the rotational frequency.
With the data at hand, and the priors defined, the analysis can now be run. It is recommended to run
by setting up a configuration file, although as mentioned equivalent command line arguments can be
passed to cwinpy_pe (or a combination of a configuration file and command line arguments may
be useful if defining some fixed setting for many analyses in the file, but making minor changes for
individual cases on the command line). A configuration file for this example is shown below, with
comments describing the parameters given inline:
# configuration file for Example 1
# The path to the TEMPO(2)-style pulsar parameter file
par-file=PULSAR08.par
# The name of the detector from which the data comes
detector=H1
# The path to the data file for the given detector. This could equivalently be
# given (and the 'detector' argument omitted) with:
# data-file=[H1:fine-H1-PULSAR08.txt.gz]
# or
# data-file={'H1': 'fine-H1-PULSAR08.txt.gz'}
# or using the 'data-file-2f' argument to be explicit about the
# gravitational-wave frequency being two times the rotation frequency
data-file=fine-H1-PULSAR08.txt.gz
# The output directory for the results (this will be created if it does not exist)
outdir=example1
# A prefix for the results file name
label=example1
# The Bayesian stochastic sampling algorithm (defaults to dynesty if not given)
sampler=dynesty
# Keyword arguments for the sampling algorithm
sampler-kwargs={'Nlive': 1000, 'plot': True}
# Show "true" signal values on the output plot (as we know this data contains a simulated signal!)
show-truths = True
# The path to the prior file
prior=example1_prior.txt
Note
When using the dynesty sampler (as wrapped through
bilby) it will default to use the rwalk sampling
method. This has been found to work well and be the quickest option for normal running. A
discussion of the bilby-specific different dynesty sampling options can be found
here,
while discussion of the options in dynesty itself can be found
here.
The analysis can then be run using:
cwinpy_pe --config example1_config.ini
which should only take a few minutes, with information on the run output to the terminal.
This will create a directory called example1 containing: the results as a bilby Results
object saved, by default, in an HDF5
format file called example1_result.hdf5 (see here for information on reading
this information within Python); and (due to the setting of 'plot': True in the
sampler_kwargs dictionary), a “corner plot” in the
file example1_corner.png showing 1D and 2D marginalised posterior probability distributions for
each parameter, and pair of parameters. To instead save the results to a JSON format file you would include "save": "json" in the sampler_kwargs
dictionary. To gzip the JSON file you would include "gzip": True in the sampler_kwargs
dictionary.
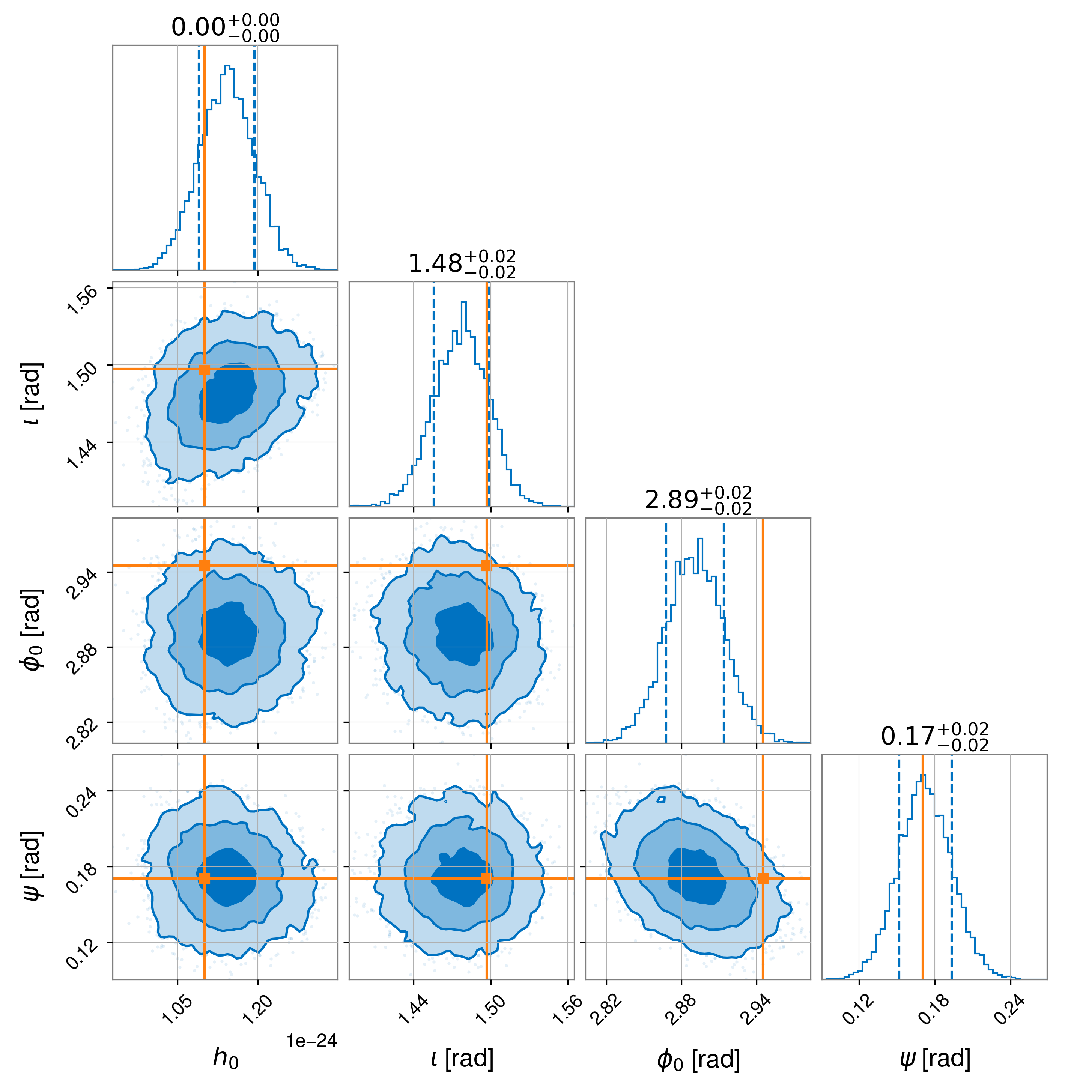
Note
The slight offset seen in the recovered phase is related to the uncompensated 150 microsec time delay in the actuation function used to generate the simulated signal as discussed in [4].
The code should also output the natural logarithm of the signal model evidence (log_evidence), noise-only model evidence
(log_noise_evidence), and Bayes factor between
those two models, and estimates of the uncertainties on the signal model evidence.
log_noise_evidence: 869768.909
log_evidence: 870014.455 ± 0.180
log_bayes_factor: 245.547 ± 0.180
If running the example you should find an identical noise evidence value, although the signal model
evidence, and therefore Bayes factor, and its uncertainty may vary slightly due to the stochastic
nature of the sampling process. These values can also be extracted from the results file called
example1_result.hdf5.
Rather than using the configuration file, all the arguments could be given on the command line (although using the configuration file is highly recommended), with the following command:
cwinpy_pe --detector H1 --par-file PULSAR08.par --data-file fine-H1-PULSAR08.txt.gz --outdir example1 --label example1 --sampler dynesty --sampler-kwargs "{'Nlive':1000,'sample':'rwalk','plot':True}" --prior example1_prior.txt --show-truths
where it should be noted that the --sampler-kwargs dictionary argument must be given within
quotation marks.
Example: multi-detector data#
In this example we will replicate the analysis from the first example, but will use O1 data from more than one detector. It will again look at the hardware injection signal named PULSAR8 and use the same parameter file as given above.
The data we will use in this example is a short segment (between GPS times of 1132444817 and
1136398891) from both the LIGO Hanford detector (abbreviated to
“H1”) and the LIGO Livingston detector (abbreviated to “L1”).
Both sets of data have been heterodyned using the known phase evolution of the simulated signal (see
the description here), and low-pass filtered and down-sampled to a rate of
one sample per minute. The data files (in a gzipped format) can be downloaded here:
fine-H1-PULSAR08.txt.gz and
fine-L1-PULSAR08.txt.gz. We will use an identical prior
file to that in the first example, but rename it example2_prior.txt.
The configuration file for this example is shown below, with comments describing the parameter given inline:
# configuration file for Example 2
# The path to the TEMPO(2)-style pulsar parameter file
par-file=PULSAR08.par
# The name of the detectors from which the data comes
detector=[H1, L1]
# The path to the data file for the given detector. This could equivalently be
# given (and the 'detector' argument omitted) with:
# data-file=[H1:fine-H1-PULSAR08.txt.gz, L1:fine-L1-PULSAR08.txt.gz]
# or
# data-file={'H1': 'fine-H1-PULSAR08.txt.gz', 'L1': 'fine-L1-PULSAR08.txt.gz'}
# or using the 'data-file-2f' argument to be explicit about the
# gravitational-wave frequency being two times the rotation frequency
data-file=[fine-H1-PULSAR08.txt.gz, fine-L1-PULSAR08.txt.gz]
# The output directory for the results (this will be created if it does not exist)
outdir=example2
# A prefix for the results file name
label=example2
# The Bayesian stochastic sampling algorithm (defaults to dynesty if not given)
sampler=dynesty
# Keyword arguments for the sampling algorithm
sampler-kwargs={'Nlive': 1000, 'plot': True}
# Show "true" signal values on the output plot (as we know this data contains a simulated signal!)
show-truths = True
# The path to the prior file
prior=example2_prior.txt
The analysis can then be run using:
cwinpy_pe --config example2_config.ini
This will create a directory called example2 containing: the results as a bilby Results
object saved, by default, in an HDF5 format file called
example2_result.hdf5 (see here for information on reading
this information within Python); and (due to the setting of 'plot': True in the
sampler_kwargs dictionary), a “corner plot” in the
file example2_corner.png showing 1D and 2D marginalised posterior probability distributions for
each parameter, and pair of parameters.
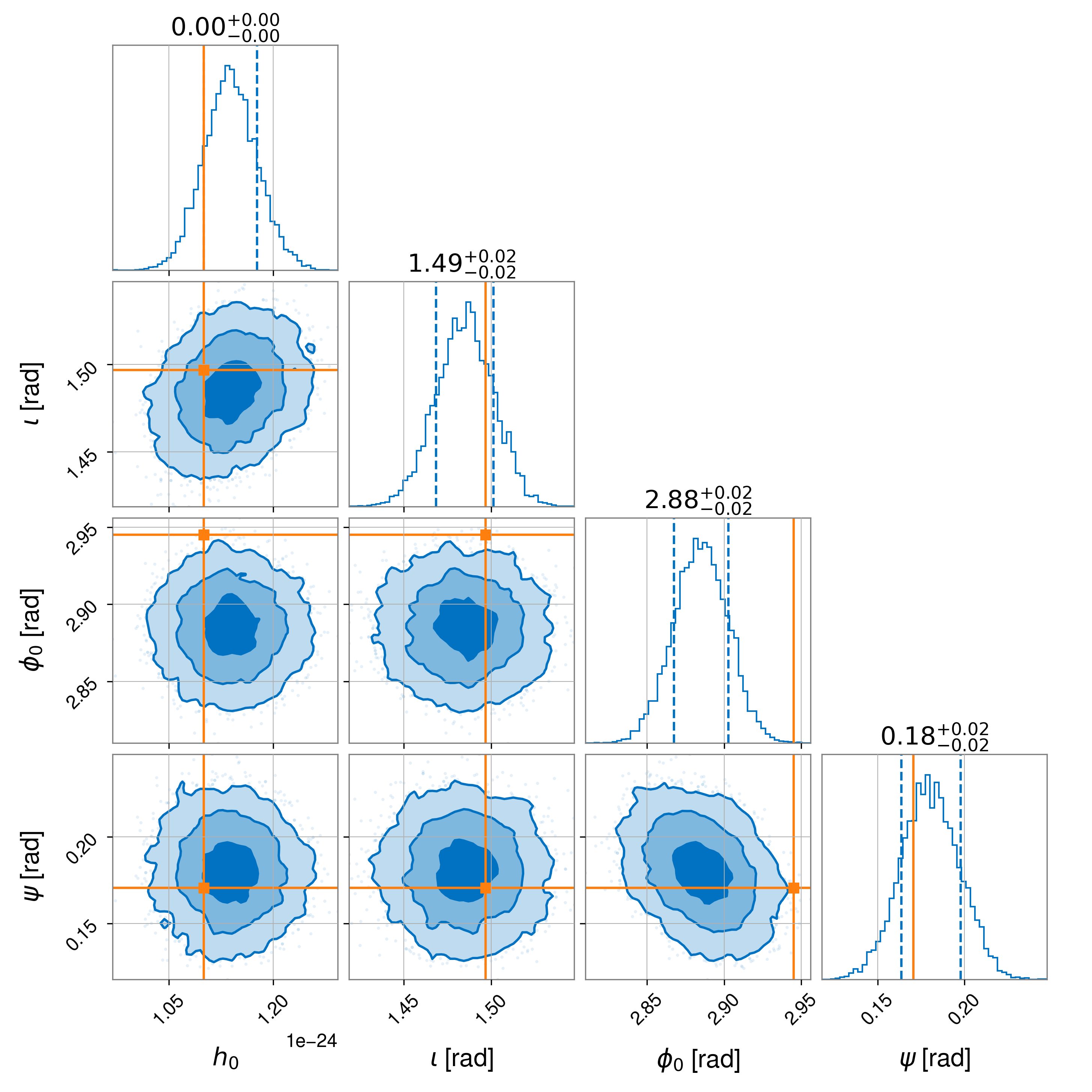
Note
The slight offset seen in the recovered phase is related to the uncompensated 150 microsec time delay in the actuation function used to generate the simulated signal as discuss in [4].
The natural logarithms of the signal model evidence (log_evidence), noise-only model evidence
(log_noise_evidence) and Bayes factor (log_bayes_factor) output for this example are
log_noise_evidence: 1492439.107
log_evidence: 1492888.344 ± 0.186
log_bayes_factor: 449.237 ± 0.186
If running the example you should find an identical noise evidence value, although the signal model
evidence, and therefore Bayes factor, and its uncertainty may vary slightly due to the stochastic
nature of the sampling process. These values can also be extracted from the results file called
example2_result.hdf5.
The equivalent full command line arguments that could be used are:
cwinpy_pe --detector H1 --detector L1 --par-file PULSAR08.par --data-file fine-H1-PULSAR08.txt.gz --data-file fine-L1-PULSAR08.txt.gz --outdir example2 --label example2 --sampler dynesty --sampler-kwargs "{'Nlive':1000,'sample':'rwalk','plot':True}" --prior example2_prior.txt --show-truths
Example: a simulated transient-continuous signal#
It is interesting to consider signals that do not have a constant amplitude, but are transitory on time scales of days-to-weeks-months (e.g., [8], [9], [10]); so-called “transient-continuous” signals. These might occur following a pulsar glitch [11]. CWInPy is able to simulate and infer the parameters of two classes of these signals, which use the normal continuous signal model modulated by a particular window function:
a rectangular window where the signal abruptly turns on then off;
an exponentially decaying window, where there is an abrupt start followed by an exponential decay.
Both models are defined by a start time, e.g., the time of an observed pulsar glitch, and a timescale \(\tau\), which defines the duration of the rectangular window model and the decay time constant for the exponential window model.
In this example, we will simulate a transient signal with a rectangular window in data from the both the LIGO Hanford detector (abbreviated to “H1”) and the LIGO Livingston detector between 01:46:25 on 14th Sept 2011 (a GPS time of 1000000000) and 01:46:25 on 18th Sept 2011.
To simulate a transient signal, the Tempo(2)-style pulsar parameter (.par) file needs to
contain the following parameters:
TRANSIENTWINDOWTYPE: this can beRECT(rectangular window) orEXP(exponential window);TRANSIENTSTARTTIME: the time at which the signal “turns-on”. This should be give as in Modified Julian Day (MJD) format, which is how glitch times are defined in Tempo(2);TRANSIENTTAU: the signal duration (rectangular window) or decay time constant (exponential window) in days.
For this example, the .par file we used defined a model with a rectangular window. It and can
be downloaded here and is reproduced below.
NAME JTRANSIENT
PSRJ JTRANSIENT
F0 234.5678
F1 -1.34e-11
RAJ 03:25:33.5
DECJ -13:25:07.9
PEPOCH 56786
H0 1.8e-25
COSIOTA -0.45
PSI 1.1
PHI0 2.4
TRANSIENTWINDOWTYPE RECT
TRANSIENTSTARTTIME 55818.573900462965
TRANSIENTTAU 1.5
To estimate the parameters of the transient signal model they must be included in the file defining
the required prior probability distributions. The prior file we use is reproduced below and can be
downloaded here:
# define priors on: the gravitational-wave amplitude, inclination angle,
# initial phase and polarisation angle
h0 = Uniform(name='h0', minimum=0, maximum=1e-22, latex_label='$h_0$')
iota = Sine(name='iota', minimum=0., maximum=np.pi, latex_label='$\iota$', unit='rad')
phi0 = Uniform(name='phi0', minimum=0, maximum=np.pi, latex_label='$\phi_0$', unit='rad')
psi = Uniform(name='psi', minimum=0, maximum=np.pi / 2, latex_label='$\psi$', unit='rad')
transientstarttime = Gaussian(name='transientstarttime', mu=55818.573900462965, sigma=0.5, latex_label='$t_0$', unit='d')
transienttau = Uniform(name='transienttau', minimum=0.1, maximum=3.0, latex_label='$\\tau$', unit='d')
If setting the TRANSIENTSTARTTIME and TRANSIENTTAU to use MJD and days, respectively, in the
prior file (to be consistent with the .par file) then the unit key for each prior must be
set to d (for day). Otherwise the values will be expected in GPS seconds and seconds. In this
case, a Gaussian prior is used for the start time with a mean given by the actual simulated start
time and a standard deviation of 0.5 days, and a uniform prior is used for the duration within a
range from 0.1 to 3 days.
Note
You can use the astropy.time.Time class to convert between GPS and MJD, e.g.:
>>> from astropy.time import Time
>>> mjd = Time(1234567890, format="gps", scale="tdb").mjd
or vice versa:
>>> gps = Time(1234567890, format="mjd", scale="tdb").gps
A configuration file that can be passed to cwinpy_pe for this example is shown below, with
comments describing the parameters given inline:
# configuration file for Example 3
# The paths to the TEMPO(2)-style injection file
par-file=TRANSIENT.par
inj-par=TRANSIENT.par
# The start and end times of the simulated data
fake-start=1000000000
fake-end=1000345600
# Use design curve ASD for simulated noise
fake-asd=[H1, L1]
# The output directory for the results (this will be created if it does not exist)
outdir=example3
# A prefix for the results file name
label=example3
# The Bayesian stochastic sampling algorithm (defaults to dynesty if not given)
sampler=dynesty
# Keyword arguments for the sampling algorithm
sampler-kwargs={'Nlive': 1000, 'plot': True}
# Show "true" signal values on the output plot (as we know this data contains a simulated signal!)
show-truths = True
# The path to the prior file
prior=example3_prior.txt
This can then be run with:
cwinpy_pe --config example3_config.ini
which produces the following posteriors:
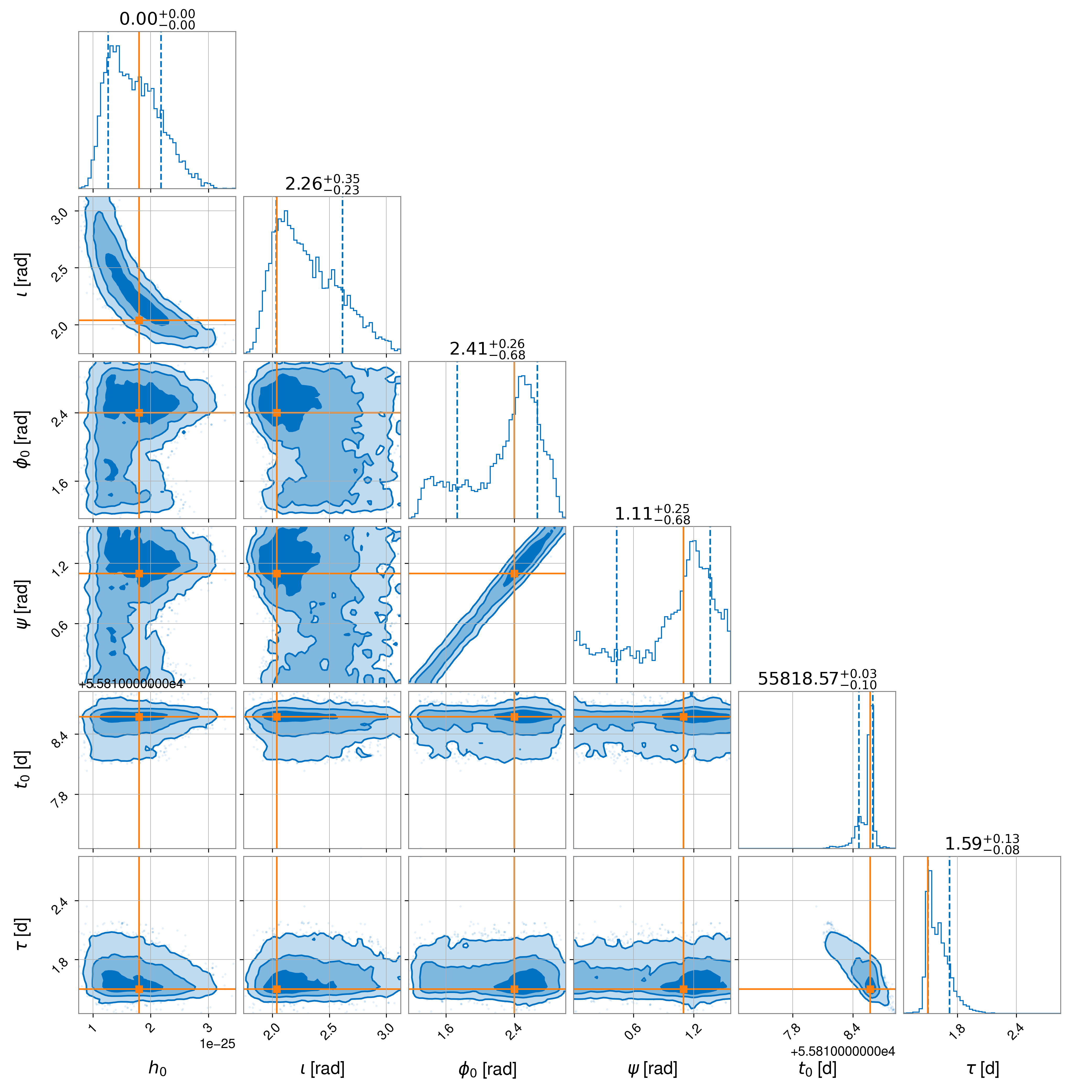
and the following signal model and noise model log evidence values:
ln_noise_evidence: 1274081.150
ln_evidence: 1274102.482 +/- 0.189
ln_bayes_factor: 21.331 +/- 0.189
Running on multiple sources#
You may have multiple real sources for which you want to perform parameter estimation, or you may want to simulate data from many sources. If you have a multicore machine or access to a computer cluster with HTCondor installed you can use CWInPy to create a set of analysis jobs, in the form of an HTCondor DAG, for each source. This makes use of PyCondor, which is installed as one of the requirements for CWInPy.
To set up a DAG to analyse real data for multiple pulsars you need to have certain datasets and
files organised in a particular way. You must have a set of Tempo(2)-style pulsar parameter files,
with only one for each pulsar you wish to analyse, which each contain a PSRJ value giving the
pulsar’s name, e.g.,
PSRJ J0534+2200
You also need to have a directory structure where the heterodyned data (see here) from individual detectors are in distinct directories (if you want specify each file for
each pulsar individually in a dictionary this can be done instead, but requires more manual
editing). Also, if there is data from both the a potential signal at the sources rotation frequency
and twice the rotation frequency, then these should also be in distinct directories. The
heterodyned data file for a particular pulsar must contain the PSRJ name of the pulsar, as given
in the associated parameter file, either in the file name or the file directory path.
An example of such a directory tree structure might be:
root
├── pulsars # directory containing pulsar parameter files
├── priors # directory containing pulsar prior distribution files
├── detector1 # directory containing data for first detector
| ├── 1f # directory containing data from first detector at the source rotation frequency
| | ├── pulsar1 # directory containing data from first detector, at the rotation frequency for first pulsar (could be named using the pulsar's PSRJ name)
| | ├── pulsar2 # directory containing data from first detector, at the rotation frequency for second pulsar (could be named using the pulsar's PSRJ name)
| | └── ...
| └── 2f
| ├── pulsar1 # directory containing data from first detector, at twice the rotation frequency for first pulsar (could be named using the pulsar's PSRJ name)
| ├── pulsar2 # directory containing data from first detector, at twice the rotation frequency for second pulsar (could be named using the pulsar's PSRJ name)
| └── ...
├── detector2 # directory contain data for second detector
| └── ...
└── ...
The DAG for the analysis can be created using the cwinpy_pe_pipeline executable, which requires
a configuration file as its only input. An example configuration file, based on the above directory
tree structure is given below. Comments about each input parameter, and different potential input
options are given inline; some input parameters are also commented out using a ; if the default
values are appropriate. For more information on the various HTCondor options see the user manual.
[run]
# the base directory for the analysis **output**
basedir = root
######### Condor DAG specific inputs ########
[pe_dag]
# the location of the directory to contain the Condor DAG submission files
# (defaults to "basedir/submit")
;submit =
# the prefix of the name for the Condor DAGMan submit file (defaults to
# "dag_cwinpy_pe"). "dag" will always be prepended.
;name =
# a flag specifying whether to automatically submit the DAG after its creation
# (defaults to False)
submitdag = False
# a flag saying whether to build the DAG (defaults to True)
;build =
# set whether running on the OSG (defaults to False). If using the OSG it
# expects you to be within an IGWN conda environment or using the singularity
# container option below.
;osg =
# if wanting to run on the OSG with the latest development version of cwinpy,
# which is within a Singularity container, set this flag to True
;singularity
# if running on the OSG you can select desired sites to run on
# see https://computing.docs.ligo.org/guide/condor/submission/#DESIRED_Sites
;desired_sites =
;undesired_sites =
######## cwinpy_pe Job options ########
[pe_job]
# the location of the cwinpy_pe executable to use (defaults to try and find
# cwinpy_pe in the current user PATH)
;executable =
# set the Condor universe (defaults to "vanilla")
;universe =
# directory location for the output from stdout from the Job (defaults to
# "basedir/log")
;out =
# directory location for the output from stderr from the Job (defaults to
# "basedir/log")
;error =
# directory location for any logging information from the jobs (defaults to
# "basedir/log")
;log =
# the location of the directory to contain the Condor job submission files
# (defaults to "basedir/submit")
;submit =
# the amount of available memory request for each job (defaults to 4 Gb)
# [Note: this is required for vanilla jobs on LIGO Scientific Collaboration
# computer clusters]
;request_memory =
# the amount of disk space required for each job (defaults to 1 Gb)
# [Note: this is required for vanilla jobs on LIGO Scientific Collaboration
# computer clusters]
;request_disk =
# the number of CPUs the job requires (defaults to 1, cwinpy_pe is not
# currently parallelised in any way)
;request_cpus =
# additional Condor job requirements (defaults to None)
;requirements =
# set how many times the DAG will retry a job on failure (default to 2)
;retry =
# Job accounting group and user [Note: these are required on LIGO Scientific
# Collaboration computer cluster, but may otherwise be left out, see
; https://accounting.ligo.org/user for valid accounting tags]
;accounting_group =
accounting_group_user = albert.einstein
####### Source and solar system ephemeride files ##########
[ephemerides]
# The pulsar parameter files, where all files are expected to have the
# extension ".par". This can either be:
# - the path to a single file (if running with a single source)
# - a list of parameter files
# - a directory (or glob-able directory pattern) containing parameter files
# - a combination of a list of directories and/or files
pulsars = /root/pulsars
# Pulsar "injection" parameter files containing simulated signal parameters to
# add to the data. If not given then no injections will be performed. If given
# it should be in the same style as the "pulsars" section.
;injections =
# Locations of the Earth and Sun ephemerides. If not given then the ephemerides
# will be automatically determined from the pulsar parameter information. The
# values should be dictionaries keyed to the ephemeris type, e.g., "DE405", and
# pointing to the location of the ephemeris file.
;earth =
;sun =
######## PE specific options ########
[pe]
# The number of parallel runs for each pulsar. These will be combined to
# create the final output. This defaults to 1.
;n_parallel =
# The period for automatically restarting HTCondor PE jobs to prevent a hard
# eviction. If not given this defaults to 43200 seconds
;periodic-restart-time =
# The directory within basedir into which to output the results in individual
# directories named using the PSRJ name (defaults to "results")
;results =
# Locations of heterodyned data files produced at twice the rotation frequency
# of the source. This must be a dictionary keyed to detector names. The value
# of each detector-keyed item can be:
# - the path to a single file (if analysing one detector)
# - a directory (or glob-able directory pattern) containing (only) data files
# - a list of files (or directories/directory patterns)
# - a dictionary keyed to pulsar PSRJ names containing the full paths to the
# associated data file
# The file name or path for each dataset must contain the associated pulsar
# PSRJ name.
# This can alternatively be just given as "data-file"
data-file-2f = {"H1": "/root/detector1/2f/*/*", "L1": "/root/detector2/2f/*/*"}
# Locations of heterodyned data files produced at the rotation frequency of the
# source (if required). This must be a dictionary keyed to detector names. The value of each
# detector-keyed item can be:
# - the path to a single file (if analysing one detector)
# - a directory (or glob-able directory pattern) containing (only) data files
# - a list of files (or directories/directory patterns)
# - a dictionary keyed to pulsar PSRJ names containing the full paths to the
# associated data file
# The file name or path for each dataset must contain the associated pulsar
# PSRJ name. [Note: this is not required if only analysing data at twice the
# rotation frequency]
data-file-1f = {"H1": "/root/detector1/1f/*/*", "L1": "/root/detector2/1f/*/*"}
# GPS start and end times to crop the input data to if required. These can only
# be single values, so all files will be cropped to the same time range. If not
# given then the full data range will be used.
;crop-start =
;crop-end =
# Set a dictionary of keyword arguments to be used by the HeterodynedData class
# that the data files will be read into.
;data_kwargs = {}
# Set this boolean flag to state whether to run parameter estimation with a
# likelihood that uses the coherent combination of data from all detectors
# specified. This defaults to True.
;coherent =
# Set this boolean flag to state whether to run the parameter estimation for
# each detector independently. This defaults to False.
;incoherent =
# Flags to set to generate simulated Gaussian noise to analyse, if data files
# are not given. "fake-asd-1f" is used to produce simulated noise at the source
# rotation frequency and "fake-asd-2f" (or just "fake-asd" is used to produce
# simulated noise at twice the source rotation frequency). The values these can
# take are:
# - a list of detectors, in which case the detector's design sensitivity curve
# will be used when generating the noise for each pulsar
# - a dictionary, keyed to detector names, either giving a value that is an
# amplitude spectral density value to be used, or a file containing a
# frequency series of amplitude spectral densities to use
;fake-asd-1f =
;fake-asd-2f =
# Flags to set the start time, end time time step and random seed for the fake
# data generation. Either both 'fake-start' and 'fake-end' must be set, or
# neither should be set. Each of the time values can either be:
# - a single integer or float giving the GPS time/time step
# - a dictionary keyed to the detector names containing the value for the
# given detector
# If not given the fake data for any required detectors will start at a GPS
# time of 1000000000 and end at 1000086400 (i.e., for one day), with a time
# step of 60 seconds
;fake-start =
;fake-end =
;fake-dt =
;fake-seed =
# The prior distributions to use for each pulsar. The value of this can either
# be:
# - a single prior file (in bilby format) to use for all pulsars
# - a list of prior files, where each filename contains the PSRJ name of the
# associated pulsar
# - a directory, or glob-able directory pattern, containing the prior files,
# where each filename contains the PSRJ name of the associated pulsar
# - a dictionary with prior file names keyed to the associated pulsar
# If not given then default priors will be used. If using data at just twice
# the rotation frequency the default priors are:
# h0 = Uniform(minimum=0.0, maximum=1.0e-22, name='h0')
# phi0 = Uniform(minimum=0.0, maximum=pi, name='phi0')
# iota = Sine(minimum=0.0, maximum=pi, name='iota')
# psi = Uniform(minimum=0.0, maximum=pi/2, name='psi')
# For data at just the rotation frequency the default priors are:
# c21 = Uniform(minimum=0.0, maximum=1.0e-22, name='c21')
# phi21 = Uniform(minimum=0.0, maximum=2*pi, name='phi21')
# iota = Sine(minimum=0.0, maximum=pi, name='iota')
# psi = Uniform(minimum=0.0, maximum=pi/2, name='psi')
# And, for data at both frequencies, the default priors are:
# c21 = Uniform(minimum=0.0, maximum=1.0e-22, name='c21')
# c22 = Uniform(minimum=0.0, maximum=1.0e-22, name='c22')
# phi21 = Uniform(minimum=0.0, maximum=2*pi, name='phi21')
# phi22 = Uniform(minimum=0.0, maximum=2*pi, name='phi22')
# iota = Sine(minimum=0.0, maximum=pi, name='iota')
# psi = Uniform(minimum=0.0, maximum=pi/2, name='psi')
priors = /root/priors
# Flag to say whether to output the injected/recovered signal-to-noise ratios
# (defaults to False)
;output_snr =
# The location within basedir for the cwinpy_pe configuration files
# generated to each source (defaults to "configs")
;config =
# The stochastic sampling package to use (defaults to "dynesty")
;sampler =
# A dictionary of any keyword arguments required by the sampler package
# (defaults to None)
;sampler_kwargs =
# A flag to set whether to use the numba-enable likelihood function (defaults
# to True)
;numba =
# A flag to set whether to generate and use a reduced order quadrature for the
# likelihood calculation (defaults to False)
;roq =
# A dictionary of any keyword arguments required by the ROQ generation
;roq_kwargs =
Once the configuration file is created (called, say, cwinpy_pe_pipeline.ini), the Condor DAG dag
can be generated with:
cwinpy_pe_pipeline cwinpy_pe_pipeline.ini
This will, using the defaults and values in the above file, generate the following directory tree structure:
root
├── results # directory to contain the results for all pulsars
| ├── pulsar1 # directory to contain the results for pulsar1 (named using the PSRJ name)
| ├── pulsar1 # directory to contain the results for pulsar2 (named using the PSRJ name)
| └── ...
├── configs # directory containing the cwinpy_pe configuration files for each pulsar
| ├── pulsar1.ini # cwinpy_pe configuration file for pulsar1 (named using the PSRJ name)
| ├── pulsar2.ini # cwinpy_pe configuration file for pulsar2 (named using the PSRJ name)
| └── ...
├── submit # directory containing the DAG and job submit files
| ├── dag_cwinpy_pe.submit # Condor DAG submit file
| ├── cwinpy_pe_H1L1_pulsar1.submit # cwinpy_pe job submit file for pulsar1
| ├── cwinpy_pe_H1L1_pulsar2.submit # cwinpy_pe job submit file for pulsar2
| └── ...
└── log # directory for the job log files
By default, if passed data for multiple detectors, the parameter estimation will be performed with
a likelihood that coherently combines the data from all detectors. To also include parameter
estimation using data from each detector individually, the [pe] section of the configuration
file should contain
incoherent = True
The submit files and the final output parameter estimation files will show the combination of detectors used in the filename.
If the original cwinpy_pe_pipeline configuration file contained the line:
submitdag = True
in the [dag] section, then the DAG will automatically have been submitted, otherwise it could be
submitted with:
condor_submit_dag /root/submit/dag_cwinpy_pe.submit
Note
If running on LIGO Scientific Collaboration computing clusters the acounting_group value must
be specified and be a valid tag. Valid tag names can be found here unless custom values for a specific cluster are allowed.
Command line arguments#
The command line arguments for cwinpy_pe can be found using:
$ cwinpy_pe --help
Traceback (most recent call last):
File "/home/docs/checkouts/readthedocs.org/user_builds/cwinpy/conda/latest/bin/cwinpy_pe", line 3, in <module>
from cwinpy.pe.pe import pe_cli
File "/home/docs/checkouts/readthedocs.org/user_builds/cwinpy/conda/latest/lib/python3.12/site-packages/cwinpy/pe/__init__.py", line 1, in <module>
from .pe import pe
File "/home/docs/checkouts/readthedocs.org/user_builds/cwinpy/conda/latest/lib/python3.12/site-packages/cwinpy/pe/pe.py", line 22, in <module>
from htcondor.dags import DAG, write_dag
ModuleNotFoundError: No module named 'htcondor'